GHOST: Getting to the Bottom of Hallucinations with A Multi-round Consistency Benchmark
{kind=link}
Abstract
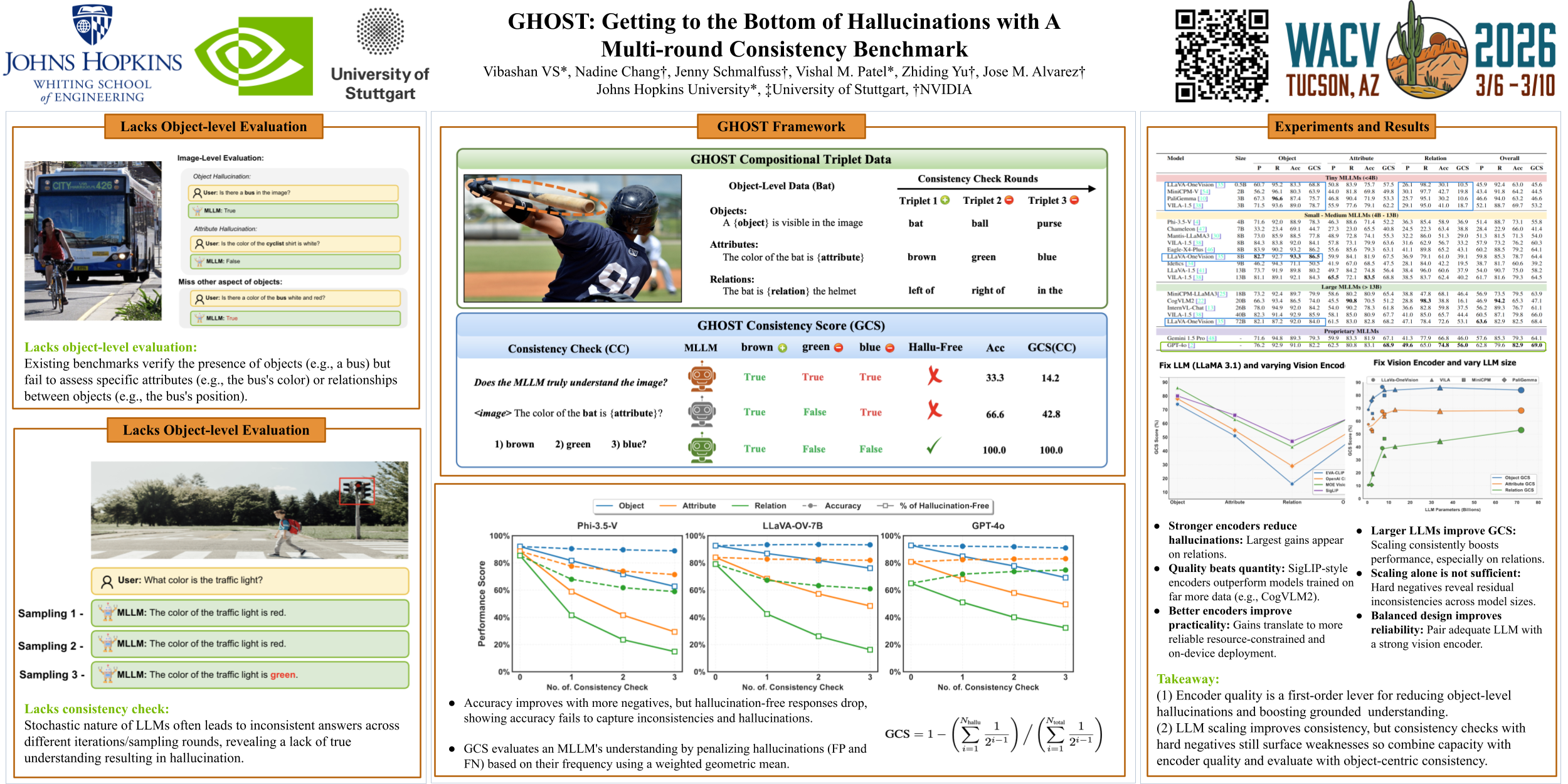
Hallucinations remain a central challenge in multimodal large language models (MLLMs), where models generate incorrect or fabricated information not present in the input. Existing benchmarks assess hallucinations only at the image level and lack a holistic object-level evaluation of types, attributes, and relations for multiple individual objects within the image. To address this limitation, we introduce GHOST, a benchmark that focuses on evaluating hallucinations at the object level. GHOST offers a fine-grained assessment by evaluating compositional triplets -- combinations of object types, attributes, and relations tied together for objects within images. We also propose a multi-round consistency-based evaluation framework and introduce the GHOST Consistency Score, a novel metric based on consistency checks using both positive (true) and hard negative (false) statements about the same object. This approach better captures hallucination tendencies by penalizing inconsistent and contradicting responses. Our benchmark includes 765 images and offers a comprehensive dataset of 38,088 questions for comprehensive hallucination evaluation. We conduct extensive experiments on 20 state-of-the-art MLLMs, including GPT-4o and Gemini-1.5-Pro and we reveal significant gaps in object-level understanding and consistency. Our analysis emphasizes the necessity of object-centric evaluation and provides valuable insights into MLLM vision encoders and their sizes in applications where accuracy and reliability are critical. Code and dataset will be released.