Pyramidal Spectrum: Frequency-based Hierarchically Vector Quantized VAE for Videos
{kind=link}
Abstract
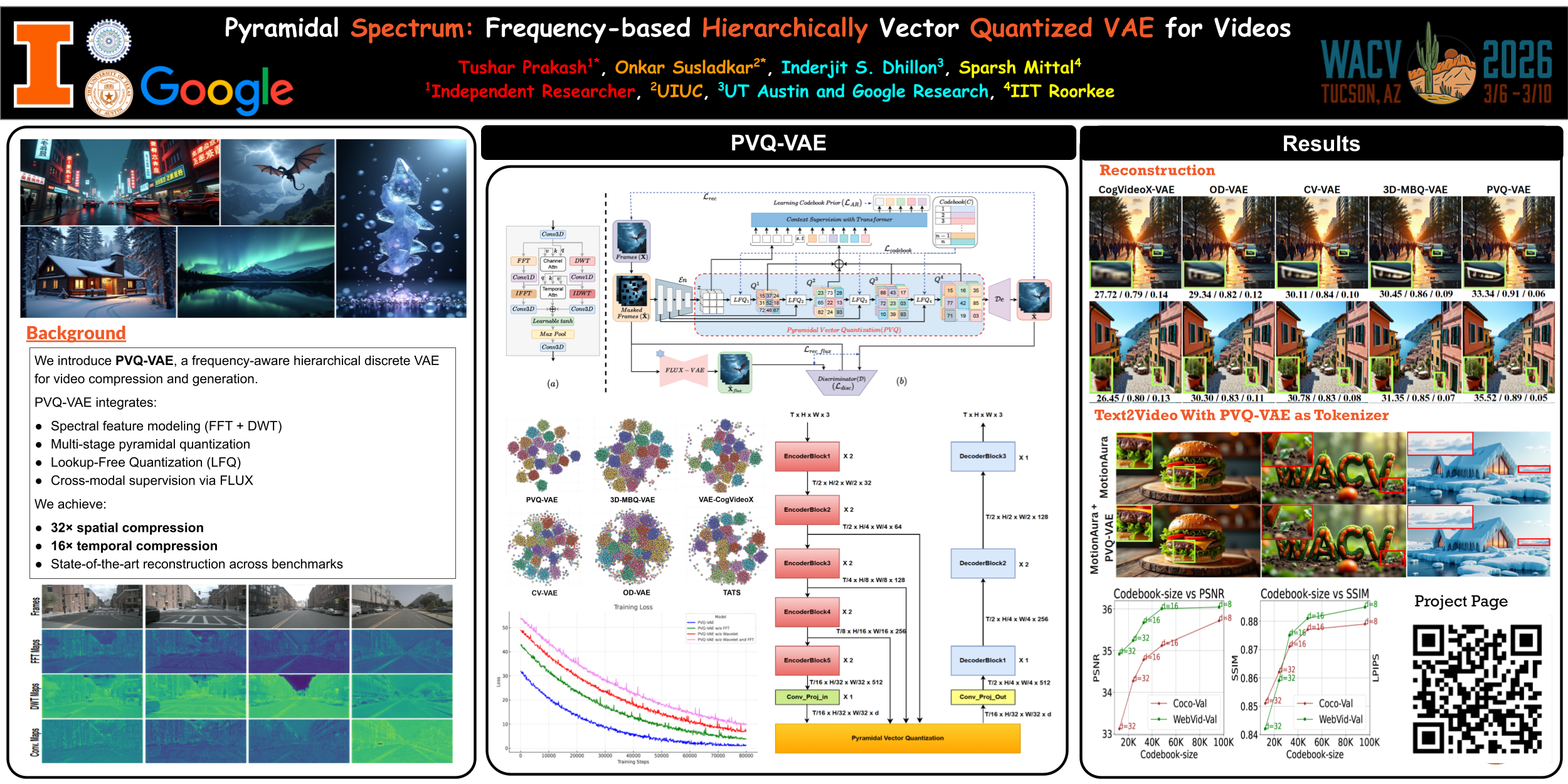
Variational Autoencoders (VAEs) form the foundation of modern video generation models. In particular, discrete latent VAEs with vector quantization have gained prominence for their superior perceptual sharpness, ability to model long-range dynamics, and efficient adaptation to downstream tasks. However, existing discrete VAEs face two key limitations: (i) a lack of frequency-domain modeling to enhance global spatiotemporal understanding, and (ii) fixed-resolution quantization schemes, preventing effective modeling of coarse-to-fine spatiotemporal hierarchies essential for video generation. To address these limitations, we propose a Pyramidal Vector Quantized Variational Autoencoder (PVQ-VAE) for videos. PVQ-VAE's encoder–decoder leverages Fast Fourier Transform and Discrete Wavelet Transform to capture global semantics and multi-scale local details jointly. We introduce Pyramidal Vector Quantization (PVQ), a hierarchical quantization scheme that discretizes features at multiple resolutions to better capture multi-scale information. To further boost fidelity, we introduce a cross-modal contrastive loss guided by a pretrained high-resolution image VAE. PVQ-VAE achieves state-of-the-art performance on WebVid-val, COCO-val, and MCL-JCV, reconstructing videos with high perceptual quality at up to 32× spatial and 16× temporal compression.