CLIP-UP: CLIP-Based Unanswerable Problem Detection for Visual Question Answering
{kind=link}
Abstract
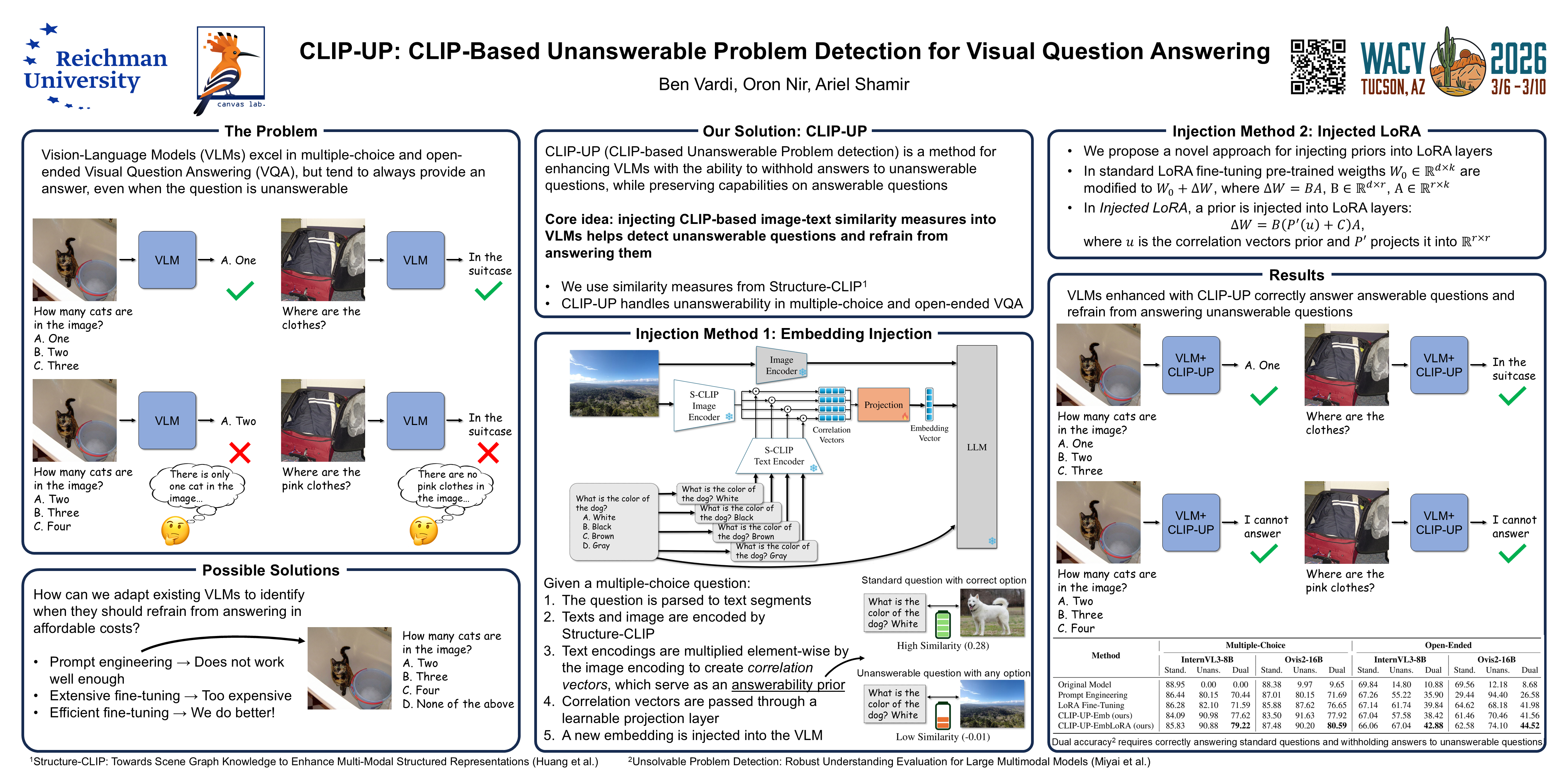
Vision-Language Models (VLMs) demonstrate remarkable capabilities in visual understanding and reasoning, such as in Visual Question Answering (VQA), where the model is asked a question related to a visual input. Still, these models can make distinctly unnatural errors, for example, providing (wrong) answers to unanswerable VQA questions, such as questions asking about objects that do not appear in the image.To address this issue, we propose CLIP-UP: CLIP-based Unanswerable Problem detection, a novel lightweight method for equipping VLMs with the ability to withhold answers to unanswerable questions. CLIP-UP leverages CLIP-based similarity measures to extract question-image alignment information to detect unanswerability, requiring efficient training of only a few additional layers, while keeping the original VLMs' weights unchanged.Tested across several models, CLIP-UP achieves significant improvements on benchmarks assessing unanswerability in both multiple-choice and open-ended VQA, surpassing other methods, while preserving original performance on other tasks. We will release our code and training data to support future research.