Explaining the Unseen: Multimodal Vision-Language Reasoning for Situational Awareness in Underground Mining Disasters
{kind=link}
Abstract
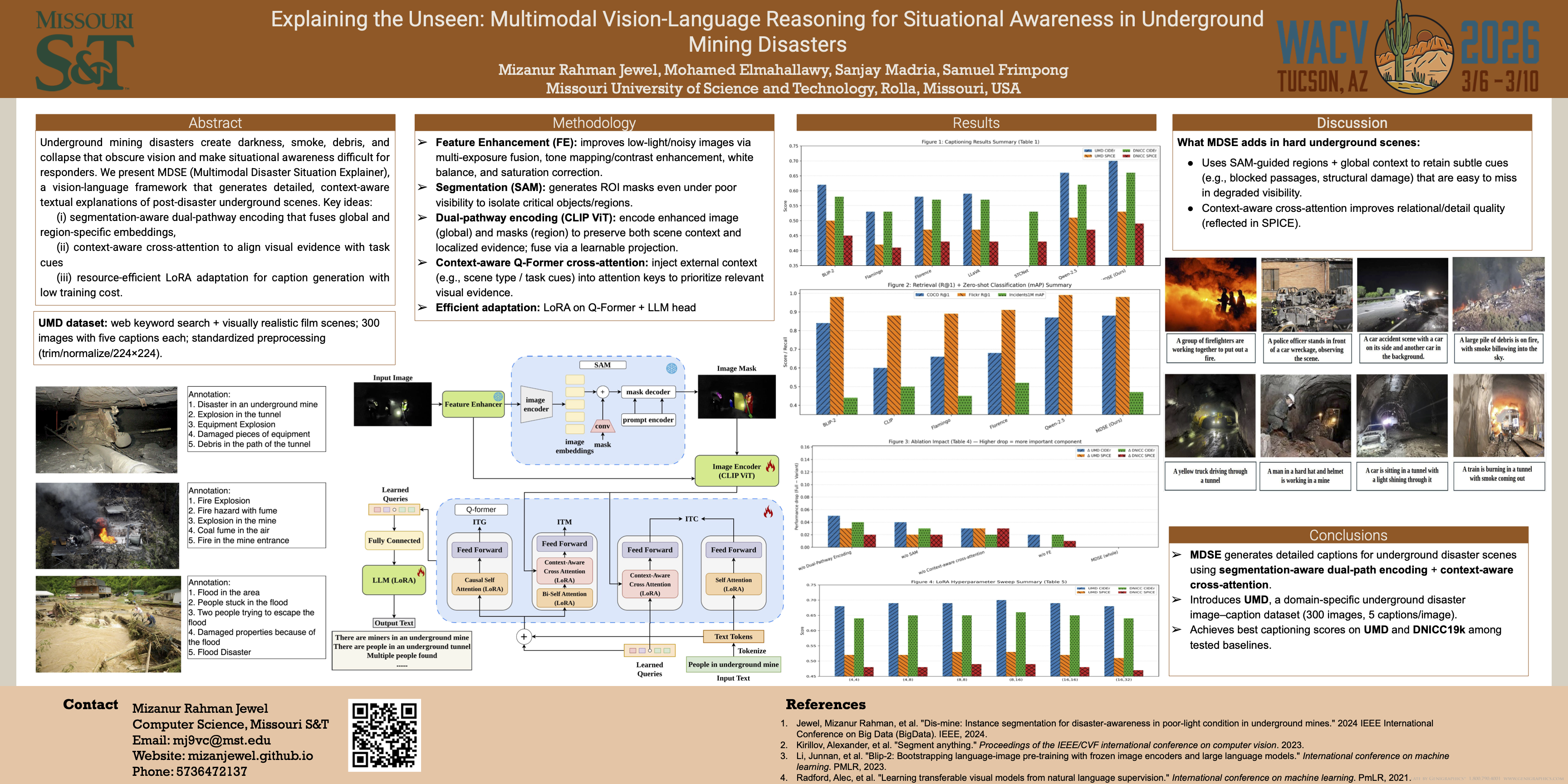
Underground mining disasters create extreme environmental conditions—pervasive darkness, dense dust, and structural collapse—that severely degrade visual information, making accurate situational awareness exceptionally difficult for both human responders and conventional vision systems. To address this, we propose MDSE, Multimodal Disaster Situation Explainer, a novel vision-language framework that automatically generates detailed textual explanations of post-disaster underground scenes. MDSE has three-fold innovations: (i) Context-Aware Cross-Attention that robustly aligns visual and textual features even under severe degradation; (ii) Segmentation-aware dual pathway visual encoding that combines global and region-focused embeddings; and (iii) Resource-Efficient Transformer-Based Language Model that generates expressive captions with minimal compute cost. Importantly, we present the Underground Mine Disaster (UMD) dataset, the first large-scale image-caption corpus of real underground disaster scenes with expert annotations, for training and rigorous evaluation. Extensive experiments on the UMD dataset and related benchmarks show that MDSE significantly outperforms state-of-the-art vision-language captioning models, producing more accurate and contextually relevant descriptions that capture crucial details in obscured environments. These results demonstrate that MDSE's multimodal architecture and domain-focused data substantially improve situational awareness for underground emergency response.