ReFineVQA: Iterative Refinement of Video Description via Feedback Generation for Video Question Answering
{kind=link}
Abstract
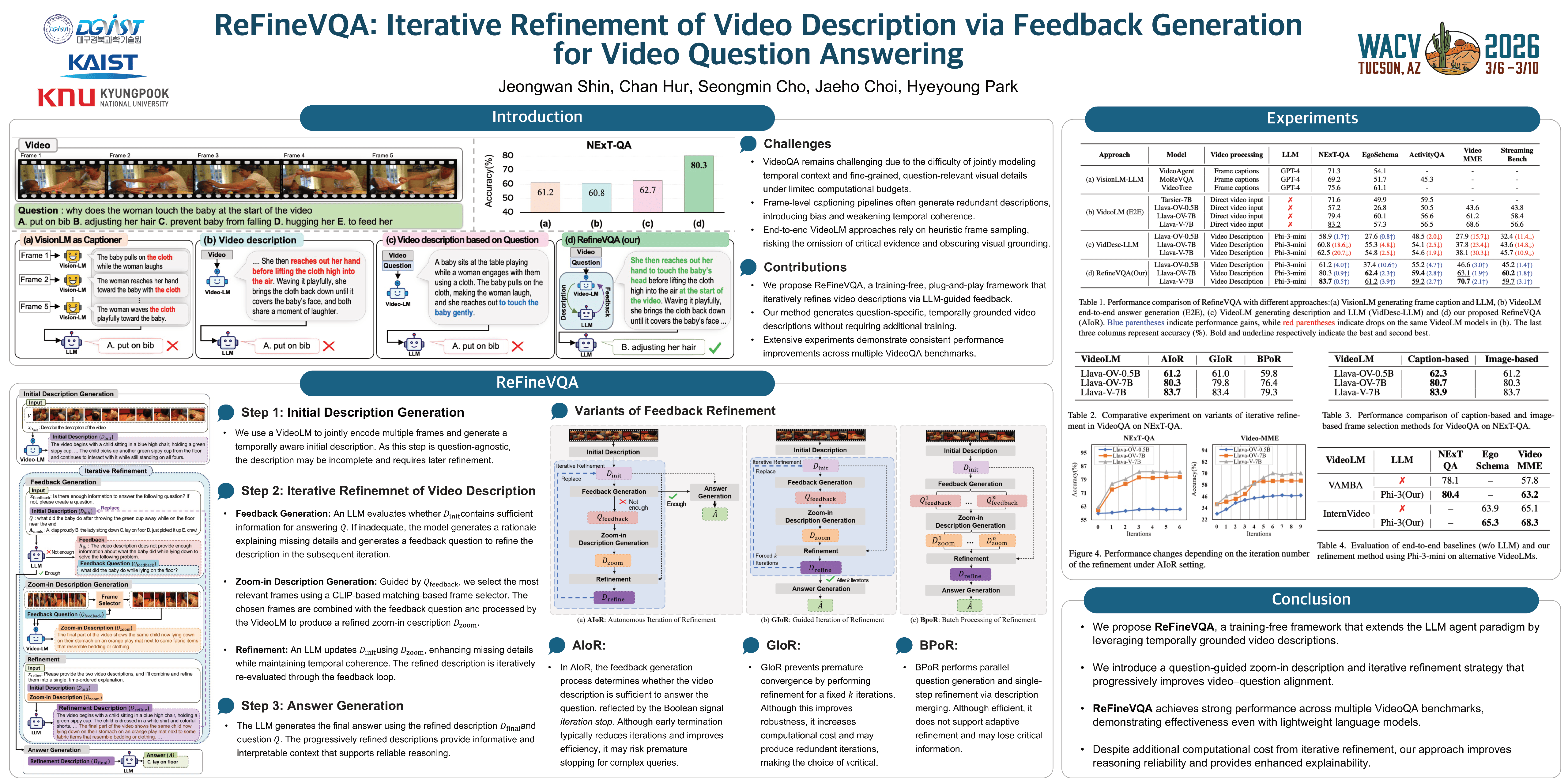
Video question answering is a non-trivial task that demands joint understanding of visual contents and linguistic questions as well as temporal reasoning across video frames. Recent agent-based approaches address this by conducting multi-step reasoning with large language models (LLMs) across frame-level captions generated by vision-language models, but encounter limited temporal coherence across frames. A possible direction based on video language models (VideoLMs) directly captures temporal dynamics via video-level descriptions, but often lacks fine-grained visual cues due to a restricted number of input frames and a large dependency on input prompts. To tackle these challenges, we propose RefineVQA, a training-free framework that can easily be plugged into existing VideoLMs with iterative, LLM-guided description refinements. Specifically, the VideoLM produces an initial description, followed by LLM feedback determining whether the description suffices for the question and guiding further visual extraction, which in turn enhances the description quality while preserving temporal context. Plugged into state-of-the-art VideoLMs, ReFineVQA yields consistent gains across diverse benchmarks--NExT-QA, EgoSchema, Video-MME, ActivityNet, and StreamingBench--even with a small external LLM of 3.8B parameters.