FG-TRACER: Tracing Information Flow in Multimodal Large Language Models in Free-Form Generation
{kind=link}
Abstract
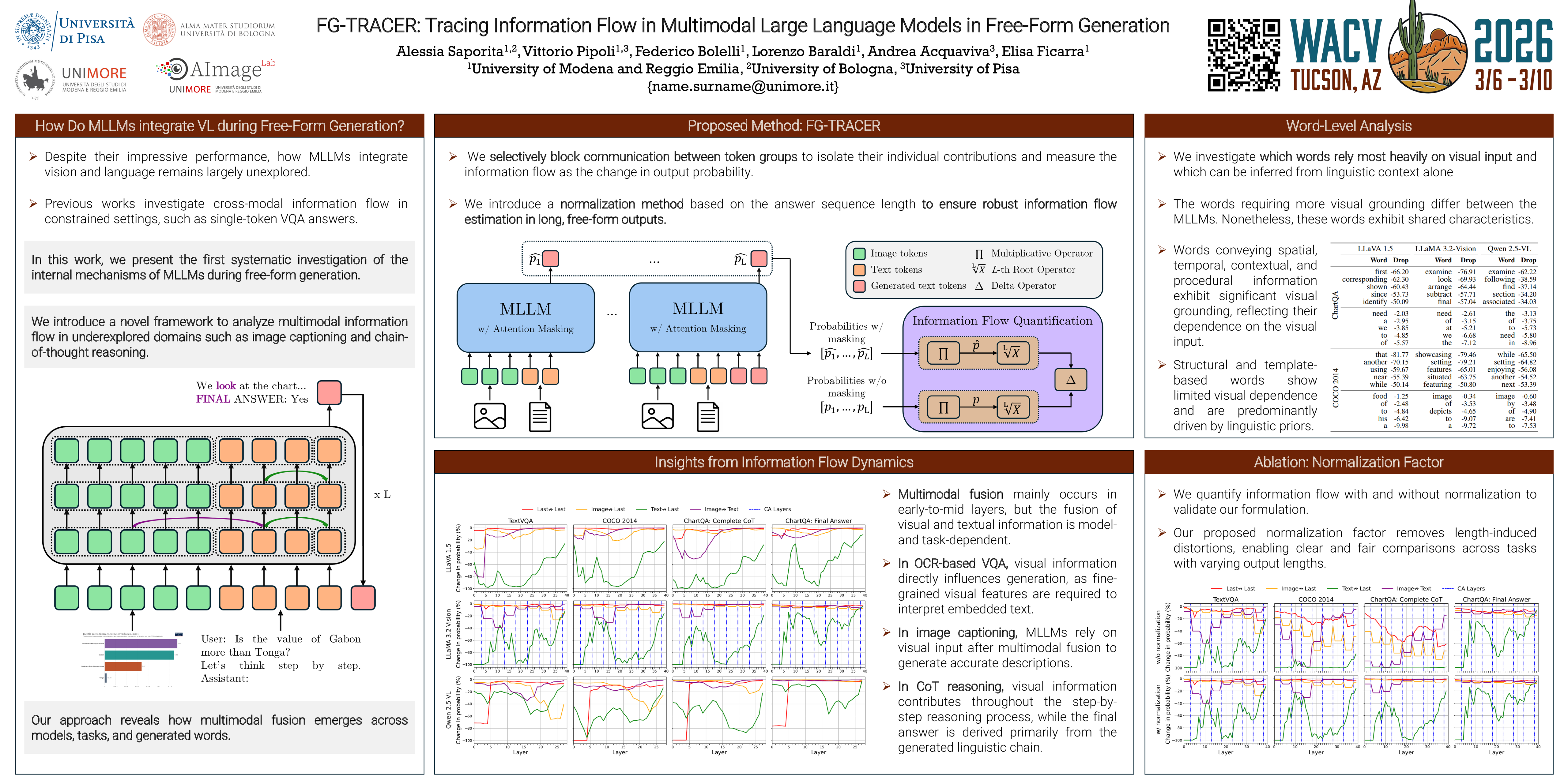
Multimodal Large Language Models (MLLMs) have achieved impressive performance across a variety of vision–language tasks. However, their internal working mechanisms remain largely underexplored. In this work, we introduce FG-TRACER, a framework designed to analyze the information flow between visual and textual modalities in MLLMs in free-form generation. Notably, our numerically stabilized computational method enables the first systematic analysis of multimodal information flow in underexplored domains such as image captioning and chain-of-thought (CoT) reasoning. We apply FG-TRACER to two state-of-the-art MLLMs—LLaMA 3.2-Vision and LLaVA 1.5—across three vision–language benchmarks—TextVQA, COCO 2014, and ChartQA—and we conduct a word-level analysis of multimodal integration. Our findings uncover distinct patterns of multimodal fusion across models and tasks, demonstrating that fusion dynamics are both model- and task-dependent. Overall, FG-TRACER offers a robust methodology for probing the internal mechanisms of MLLMs in free-form settings, providing new insights into their multimodal reasoning strategies. Our source code is publicly available at https://anonymous.4open.science/r/FG-TRACER-CB5A/.