Beyond the Encoder: Joint Encoder-Decoder Contrastive Pre-Training Improves Dense Prediction
{kind=link}
Abstract
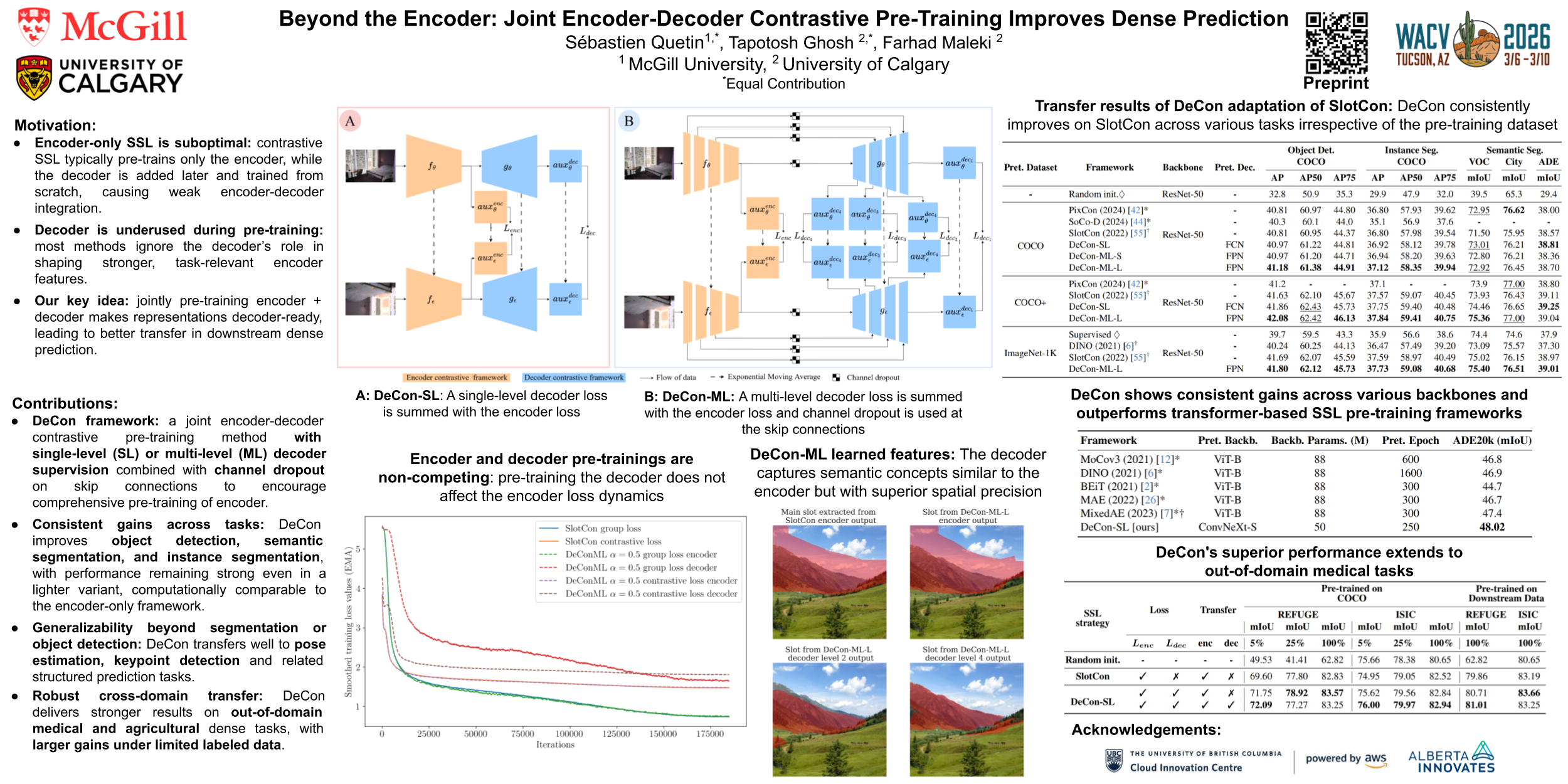
Contrastive learning methods in self-supervised settings have primarily focused on pre-training encoders, while decoders are typically introduced and trained separately for downstream dense prediction tasks. However, this conventional approach overlooks the potential benefits of jointly pre-training both encoder and decoder. In this paper, we propose DeCon, an efficient encoder-decoder self-supervised learning (SSL) framework that supports joint contrastive pre-training. We first extend existing SSL architectures to accommodate diverse decoders and their corresponding contrastive losses. Then, we introduce a weighted encoder-decoder contrastive loss with non-competing objectives to enable the joint pre-training of encoder-decoder architectures. By adapting an established contrastive SSL framework for dense prediction tasks, DeCon achieves new state-of-the-art results: on COCO object detection and instance segmentation when pre-trained on COCO dataset; across almost all dense downstream benchmark tasks when pre-trained on COCO+ and ImageNet-1K. Our results demonstrate that joint pre-training enhances the representation power of the encoder and improves performance in dense prediction tasks. This gain persists across heterogeneous decoder architectures, various encoder architectures, and in out-of-domain limited-data scenarios.