Direct Visual Grounding by Directing Attention of Visual Tokens
{kind=link}
Abstract
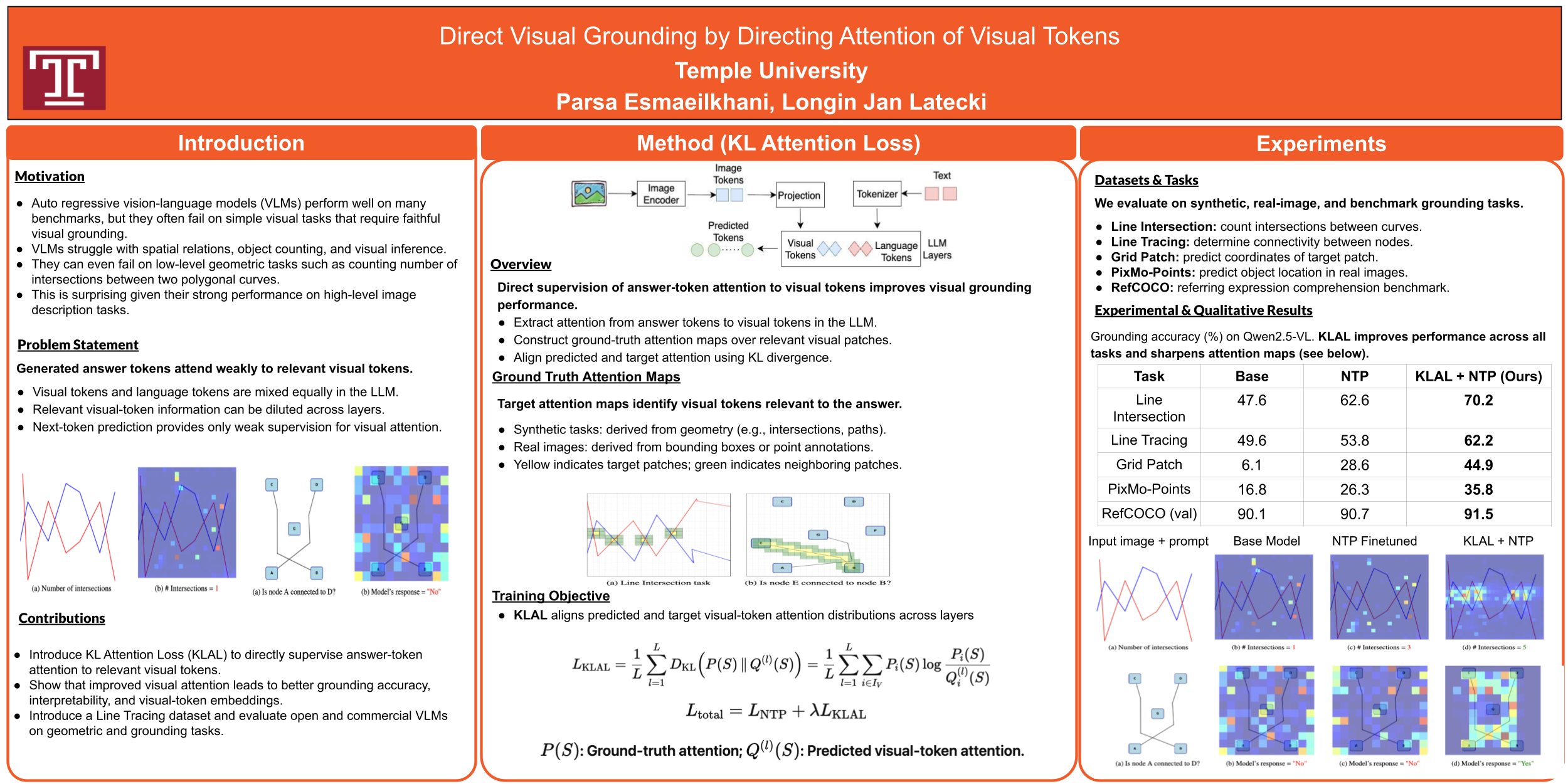
Vision Language Models (VLMs) mix visual tokens and text tokens.A puzzling issue is the fact that visual tokens most related to the query receive little to no attention in the final layers of the LLM module of VLMs from the answer tokens,where all tokens are treated equally, in particular, visual and language tokens in the LLM attention layers.This fact may result in wrong answers to visual questions, as our experimental results confirm.It appears that the standard next-token prediction (NTP) loss provides an insufficient signal for directing attention to visual tokens.We hypothesize that a more direct supervision of the attention of visual tokens to corresponding language tokens in the LLM module of VLMs will lead to improved performance on visual tasks.To demonstrate that this is indeed the case,we propose a novel loss function that directly supervises the attention of visual tokens.It directly grounds the answer language tokens in images by directing their attention to the relevant visual tokens.This is achieved by aligning the attention distribution of visual tokens to ground truth attention maps with KL divergence.The ground truth attention maps are task-specific but are generated automatically. The obtained KL attention loss (KLAL) when combined with NTPencourages VLMs to attend to relevant visual tokens while generating answer tokens.This results in notable enhancements in performance across several geometric tasks, as shown by our experimental findings.We also introduce a new dataset to evaluate the line tracing abilities of VLMs. Surprisingly, even commercial VLMs do not perform well on this task.