SVS-GAN for Semantic Synthesis of Traffic Videos for Autonomous Driving
Khaled Seyam ⋅ Julian Wiederer ⋅ Markus Braun ⋅ Bin Yang
{kind=link}
Abstract
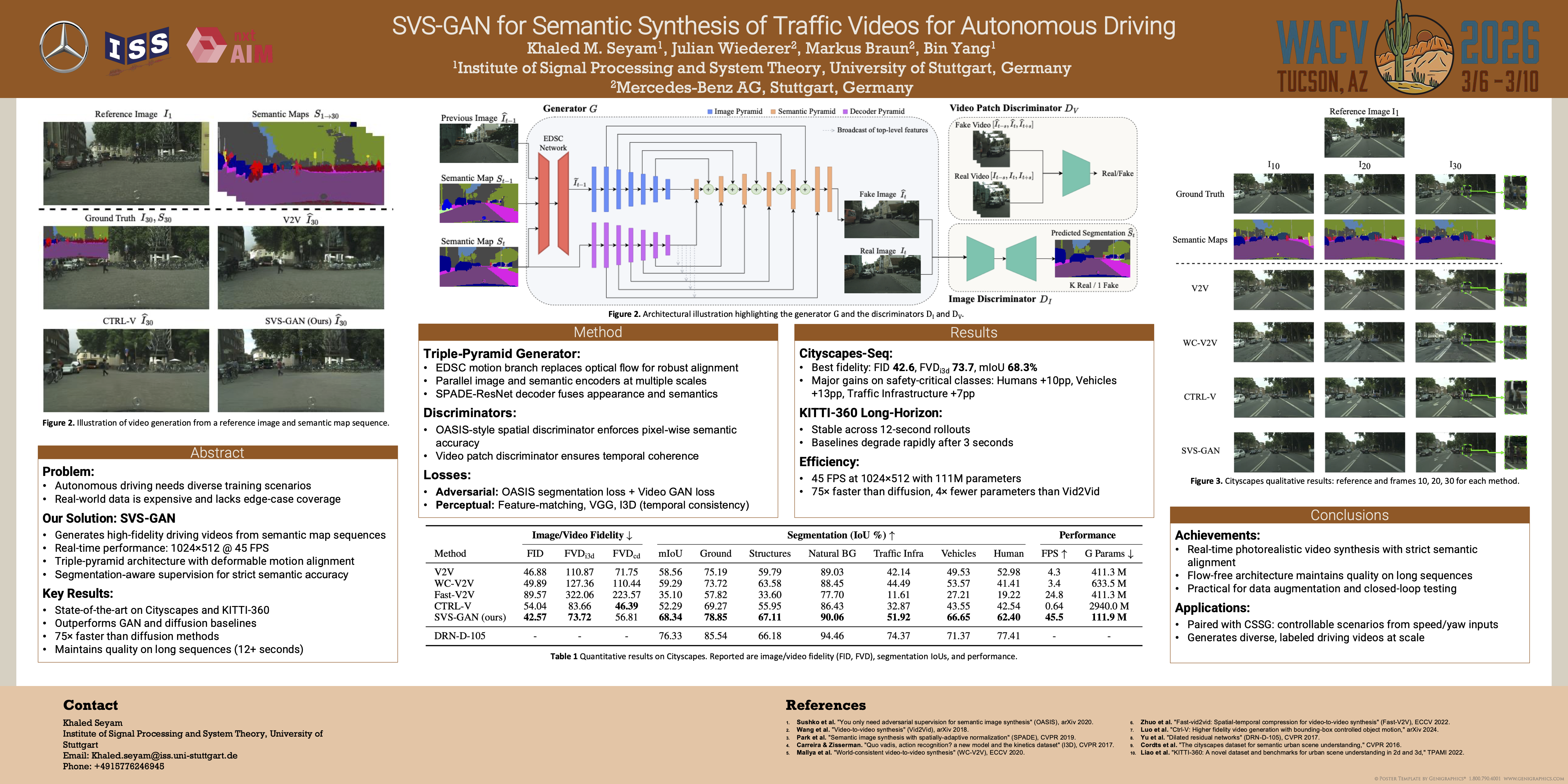
Autonomous driving demands robust perception modules trained on diverse scenarios, yet collecting and annotating real-world datasets is both expensive and often lacks sufficient coverage of all possible driving conditions. Semantic Image Synthesis (SIS)---the process of generating realistic images from semantic label maps---has proven effective for producing large-scale labeled data. However, extending SIS to the video domain as Semantic Video Synthesis (SVS), where entire sequences are generated from semantic maps, remains underexplored. We introduce SVS-GAN, a framework specifically tailored for SVS that generates high-quality, temporally coherent videos at a resolution of 1024$\times$512 in real-time (45 FPS). Our approach leverages a deformable motion triple-pyramid generator and a segmentation-aware discriminator to ensure strong semantic alignment and visual fidelity. Through this combination of tailored architecture and loss design, we bridge the gap between SIS and SVS, outperforming state-of-the-art GAN- and diffusion-based baselines on both Cityscapes and KITTI-360. When combined with a semantic-map generator, SVS-GAN enables controllable generation of diverse driving scenarios, providing a scalable source of labeled video for data augmentation and closed-loop testing.
Chat is not available.
Successful Page Load