Learning Compact Video Representations for Efficient Long-form Video Understanding in Large Multimodal Models
{kind=link}
Abstract
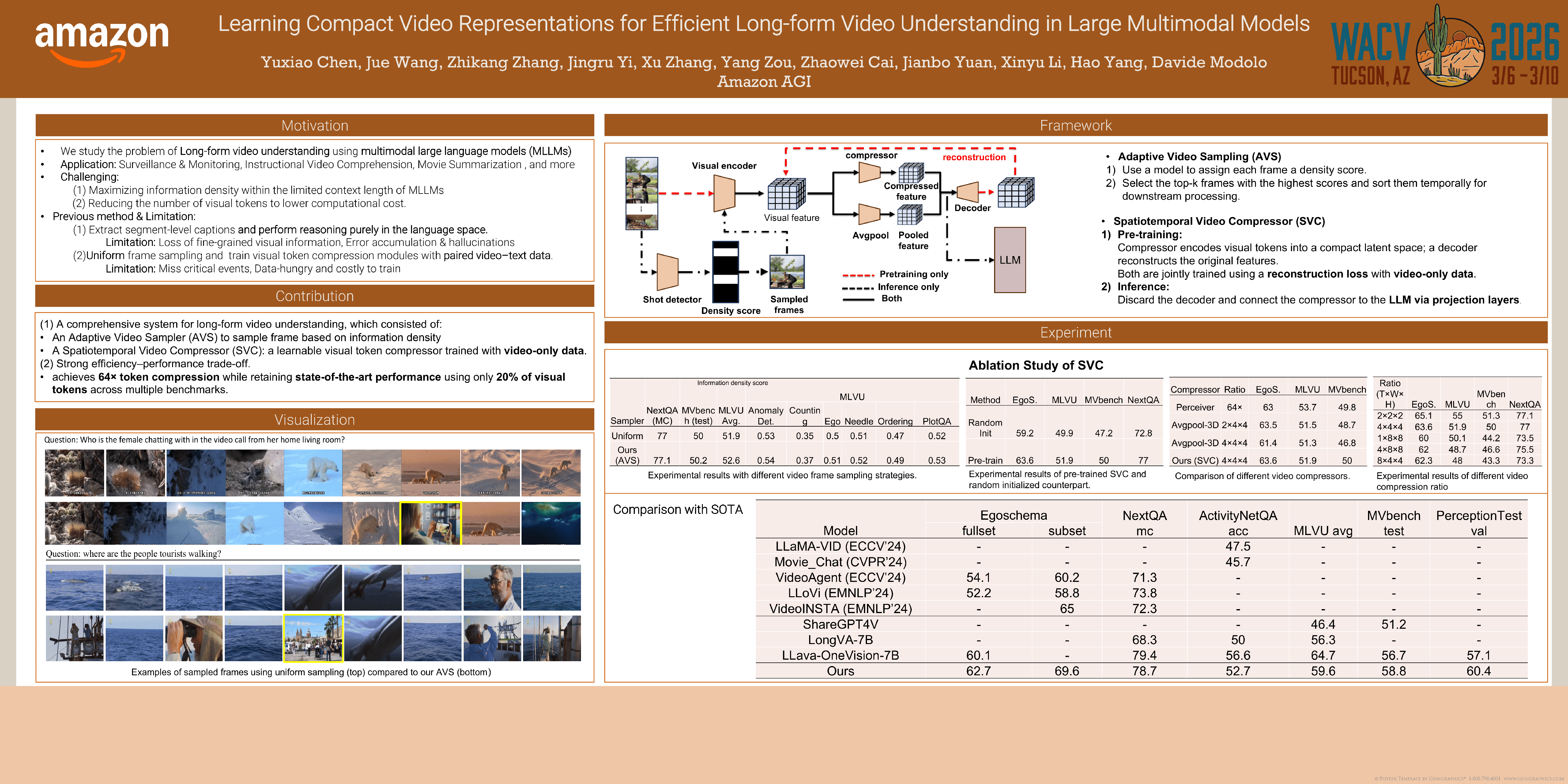
With recent advancements in video backbone architectures and the remarkable success of large language models (LLMs), long-form video understanding—analyzing videos that span tens of minutes—has become both feasible and increasingly popular. However, the inherently redundant nature of video sequences presents significant challenges for current state-of-the-art models. These challenges arise from two key aspects: 1) efficiently incorporating a larger number of frames within the memory budget, and 2) extracting discriminative information from the vast volume of input data. In this paper, we present a novel, end-to-end schema for long-form video understanding, featuring an information-density-based adaptive video sampler (AVS) and an autoencoder based spatiotemporal video compressor (SVC) integrated with a multimodal large language model (MLLM). Our proposed system offers two significant advantages: it adaptively and effectively captures essential information from video sequences with various duration, and it achieves high compression rates while preserving crucial discriminative information. The proposed framework achieves promising performance across a range of benchmarks, excelling in both long-form video understanding tasks and standard video understanding benchmarks. These results demonstrate the versatility and effectiveness of our approach, particularly in handling the complexities of the long video sequences.