CLIP’s Visual Embedding Projector is a Few-shot Cornucopia
{kind=link}
Abstract
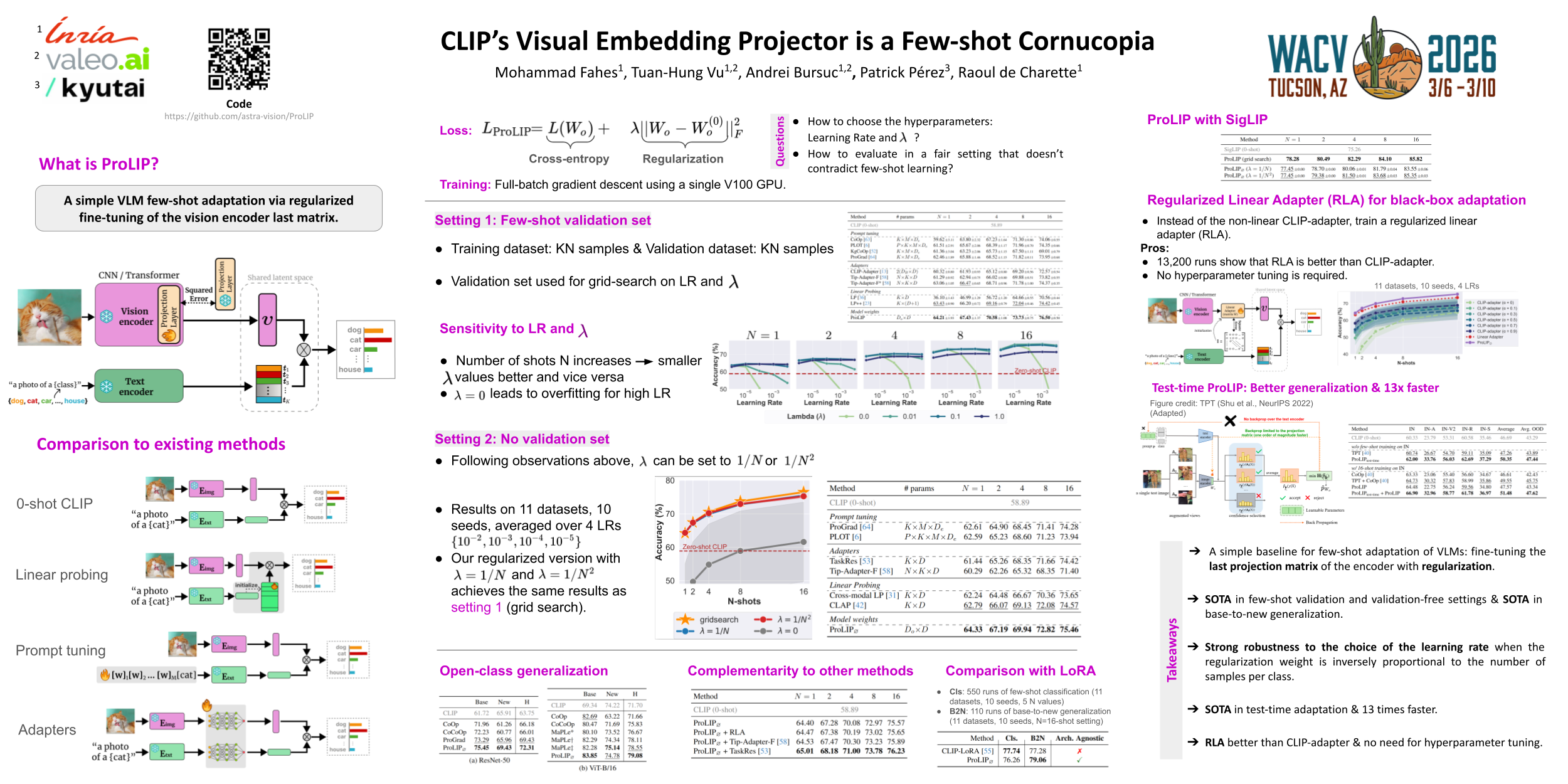
We introduce ProLIP, a simple and architecture-agnostic method for adapting contrastively pretrained vision-language models, such as CLIP, to few-shot classification. ProLIP fine-tunes the vision encoder’s projection matrix with Frobenius norm regularization on its deviation from the pretrained weights. It achieves state-of-the-art performance on 11 few-shot classification benchmarks under both ''few-shot validation'' and ''validation-free'' settings. Moreover, by rethinking the non-linear CLIP-Adapter through ProLIP’s lens, we design a regularized linear adapter that performs better, requires no hyperparameter tuning, and is less sensitive to learning rate values. Beyond few-shot classification, ProLIP excels in cross-dataset transfer, domain generalization, base-to-new class generalization, and test-time adaptation—where it outperforms prompt tuning while being an order of magnitude faster to train. Code will be made publicly available.