Similarity-aware Probabilistic Embeddings Modeling for Video-Text Retrieval
{kind=link}
Abstract
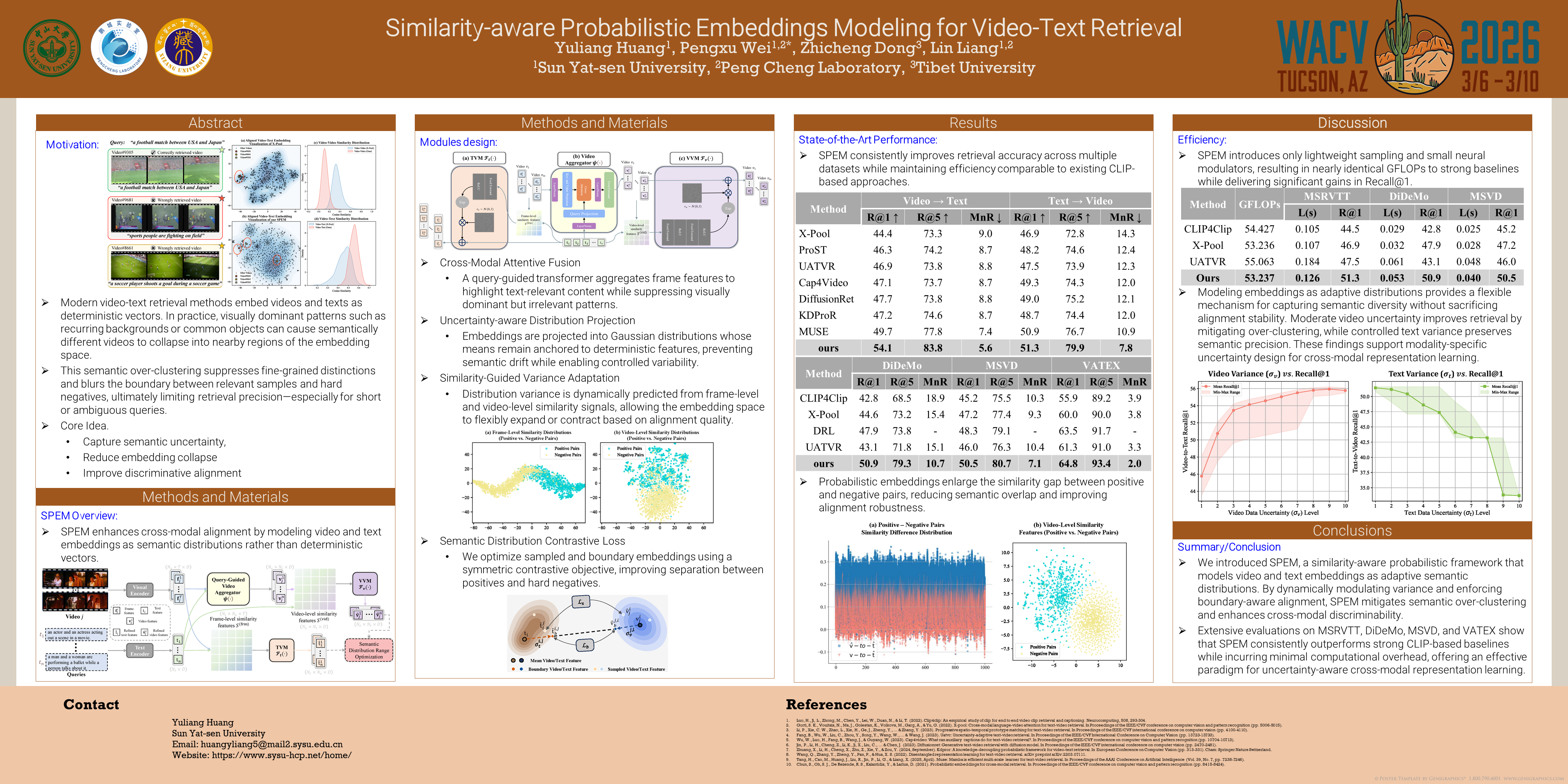
Video-text retrieval is a fundamental task in multi-modal learning, aiming to accurately retrieve videos that match given textual descriptions. While recent contrastive methods have made significant progress by embedding videos and texts into a joint space, they often suffer from semantic over-clustering—a phenomenon where semantically distinct videos are mapped to overly similar embeddings due to dominant but uninformative visual patterns (e.g., recurring backgrounds or common objects). This effect becomes particularly problematic under short or ambiguous queries, where it suppresses fine-grained semantics and degrades retrieval precision. To address this, we propose Similarity-aware Probabilistic Embeddings Modeling (SPEM), a novel framework that refines video representations by modeling them as adaptive probability distributions rather than static vectors. SPEM incorporates cross-modal attention to highlight text-relevant visual content and suppress irrelevant patterns, and leverages multi-level similarity features to dynamically adjust the embedding variance, thereby preserving subtle but critical semantic cues. To further improve alignment, we employ a Semantic-Distribution Contrastive Loss to optimize the alignment structure in the probabilistic space, encouraging more discriminative separation across hard negatives. Extensive experiments on five widely-used video-text retrieval benchmarks—MSRVTT, DiDeMo, VATEX, MSVD, and Charades—demonstrate that SPEM consistently outperforms strong CLIP-based baselines.