Mitigating Backdoor Attacks via Trigger Reconstruction and Model Hardening
{kind=link}
Abstract
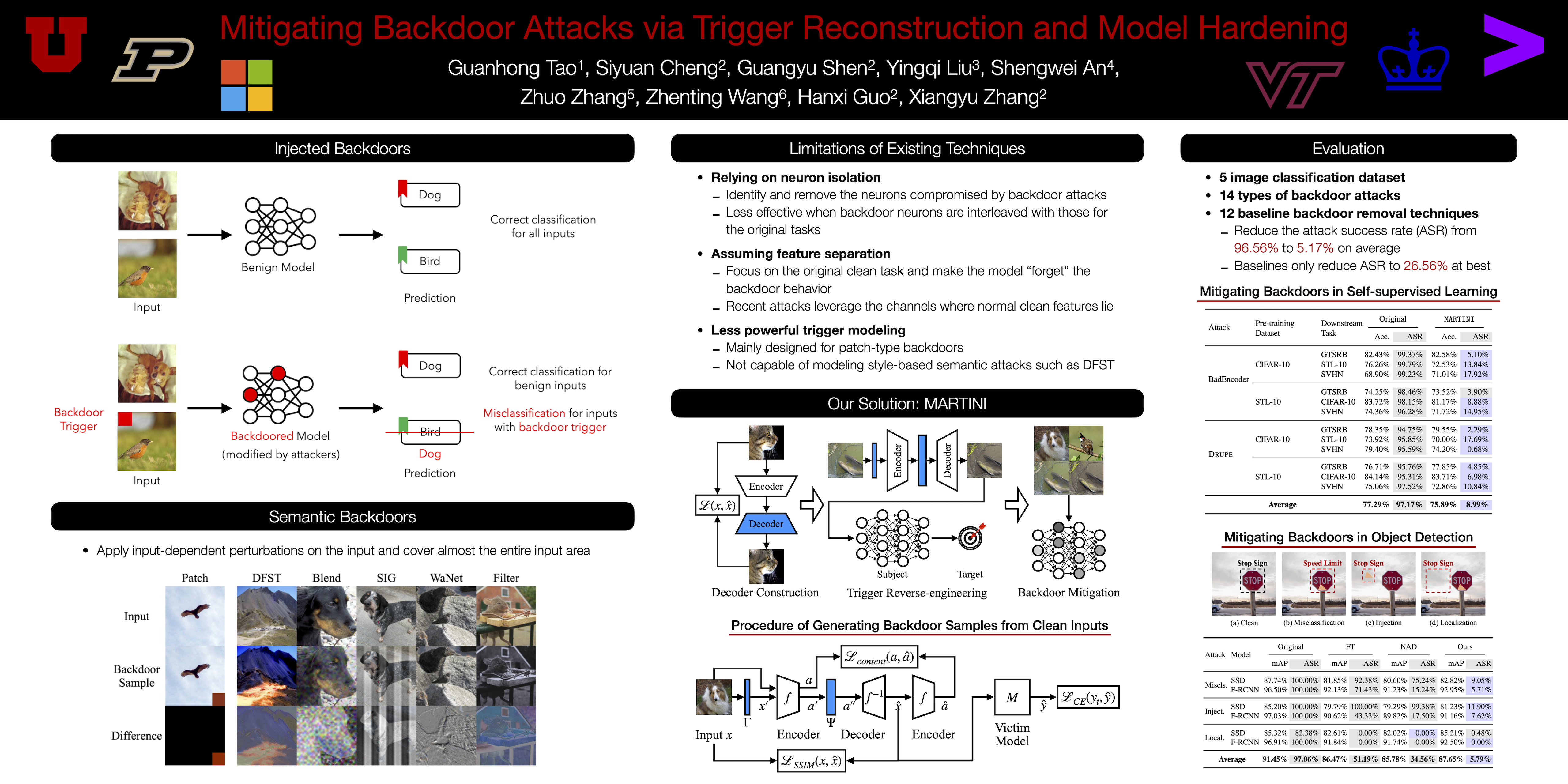
Backdoor attacks are among the most prominent security threats to deep learning models. Traditional backdoors rely on fixed trigger patterns (e.g., a red square) that existing defenses can often effectively remove. However, recent attacks embed semantic triggers that vary with the input and blend with meaningful features, rendering prior defenses ineffective. We propose MARTINI, a novel backdoor mitigation framework that addresses both traditional and semantic backdoors. MARTINI reconstructs backdoor samples via a dedicated trigger reconstruction procedure, producing malicious inputs that replicate the injected attack effect across a spectrum of attacks. Using these reconstructed samples paired with their correct labels, MARTINI then hardens the model through retraining to neutralize the targeted misclassification. Our evaluation on 14 types of backdoor attacks in image classification shows that MARTINI can reduce the attack success rate (ASR) from 96.56% to 5.17% on average, outperforming 12 state-of-the-art backdoor removal approaches, which at best reduce the ASR to 26.56%. It can also mitigate backdoors in self-supervised learning, object detection and NLP sentiment analysis.