A-V Representation Learning via Audio Shift Prediction for Multimodal Deepfake Detection and Temporal Localization
{kind=link}
Abstract
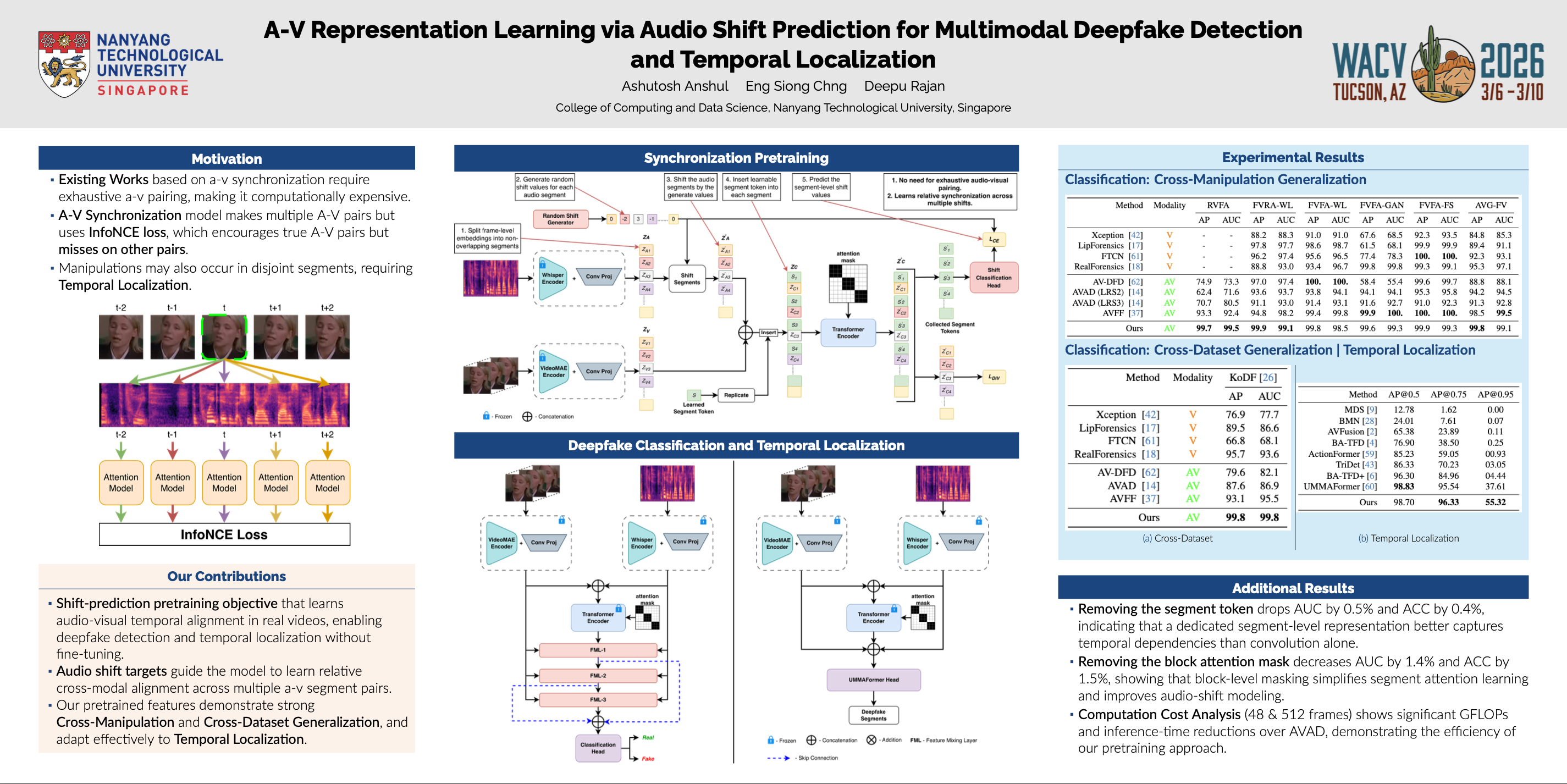
Recent multimodal deepfake detection methods typically rely on single-stage training, which can cause the model to focus on dataset-specific multimodal cues while missing important features that are helpful to detect unseen manipulations, thereby limiting generalization. While some approaches attempt to address this using self-supervised audio-visual pretraining, they may not fully exploit cross-modal temporal information. Also, they often assume that manipulations affect the entire video, ignoring more realistic cases where only short segments are altered. To overcome these limitations, we propose a two-stage training framework that first learns audio-visual temporal alignment in real videos and then uses this information to detect and localize potential deepfakes by identifying temporal inconsistencies. We propose a self-supervised shift-prediction pretraining objective to fully understand cross-modal temporal alignment across multiple temporal shifts applied to the audio input. The pretrained features enable the model to identify manipulations across entire videos as well as accurately localize deepfake segments in partially tampered content. Moreover, the pretrained components do not require task-specific fine-tuning, improving the model’s flexibility for both classification and localization. Experiments on benchmark datasets demonstrate strong within-dataset performance, robust generalization to new manipulations and datasets, and accurate temporal localization.