Gated Temporal Fusion Transformers for Robust Multi-Object Tracking
{kind=link}
Abstract
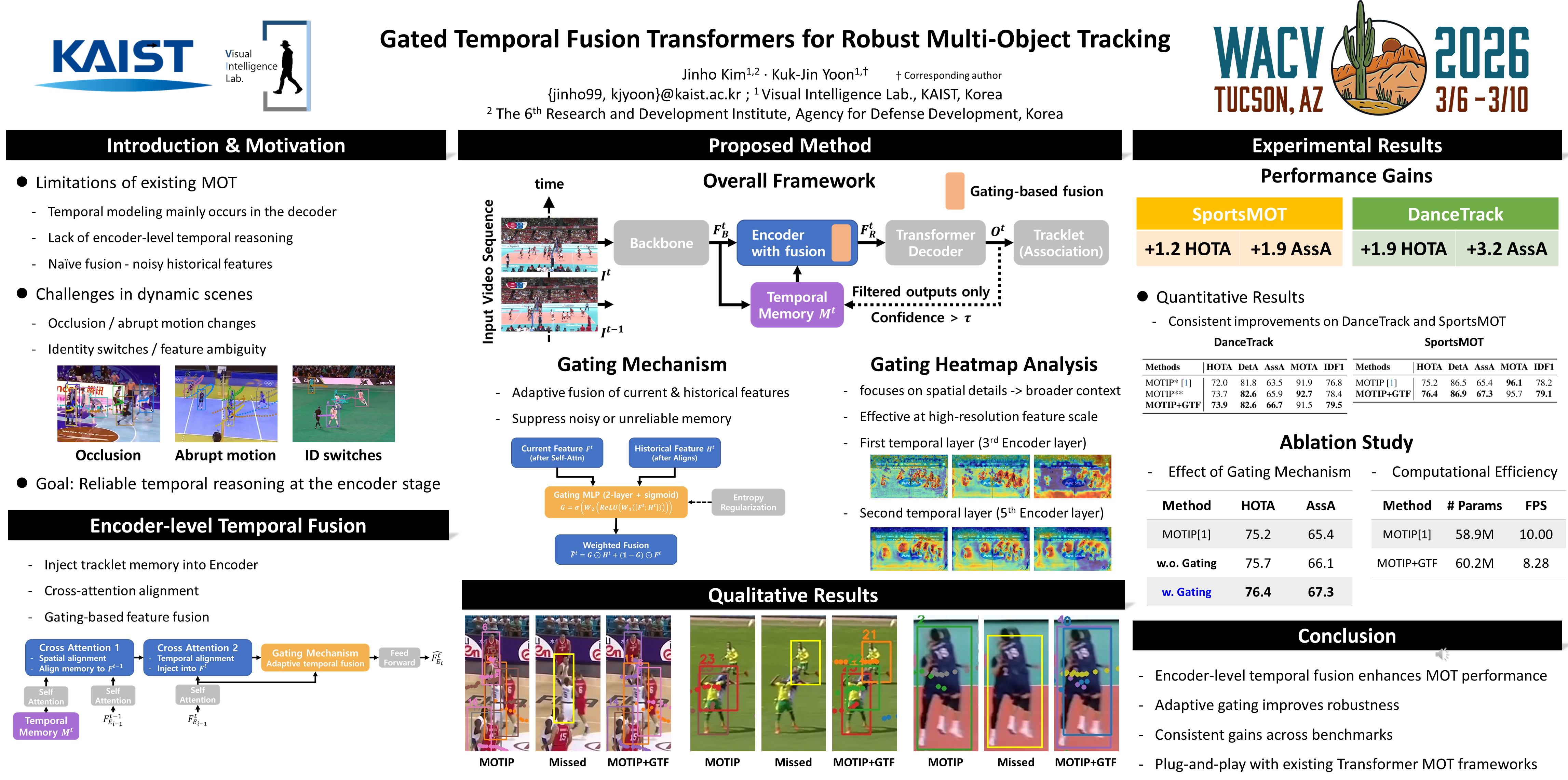
Multiple Object Tracking (MOT) in dynamic and densely populated scenes presents significant challenges due to frequent occlusions, erratic object motion, and identity switches. While recent Transformer-based approaches have successfully leveraged global attention for object detection, most rely on temporal reasoning at the decoder level, leaving encoder-stage modeling underexplored. In this work, we propose an encoder-level temporal reasoning Transformer framework that embeds historical object trajectory information into the encoder stage via a tracklet memory. The encoder module, enhanced by Attention-by-Tracking, enriches visual features with temporal priors, while the decoder leverages Tracking-by-Attention to guide identity association using learned tracklet representations. To further improve temporal consistency and object localization, we introduce a gating-based temporal feature fusion mechanism that adaptively integrates multi-frame features based on cosine similarity. Additionally, we refine reference points in the encoder using temporal cues and incorporate learnable positional embeddings to enhance detection accuracy in cluttered environments. Our method is model-agnostic and can be applied to various Transformer-based MOT frameworks. When integrated into existing models such as TransTrack, MeMOTR, and MOTIP, it yields consistent performance improvements. Extensive experiments on DanceTrack and SportsMOT benchmarks demonstrate that our approach achieves superior tracking performance, including a HOTA score of 76.4 on SportsMOT. These results validate the effectiveness of encoder-level temporal integration and adaptive feature fusion for robust multi-object tracking in real-world scenarios.