DexAvatar: 3D Sign Language Reconstruction with Hand and Body Pose Priors
{kind=link}
Abstract
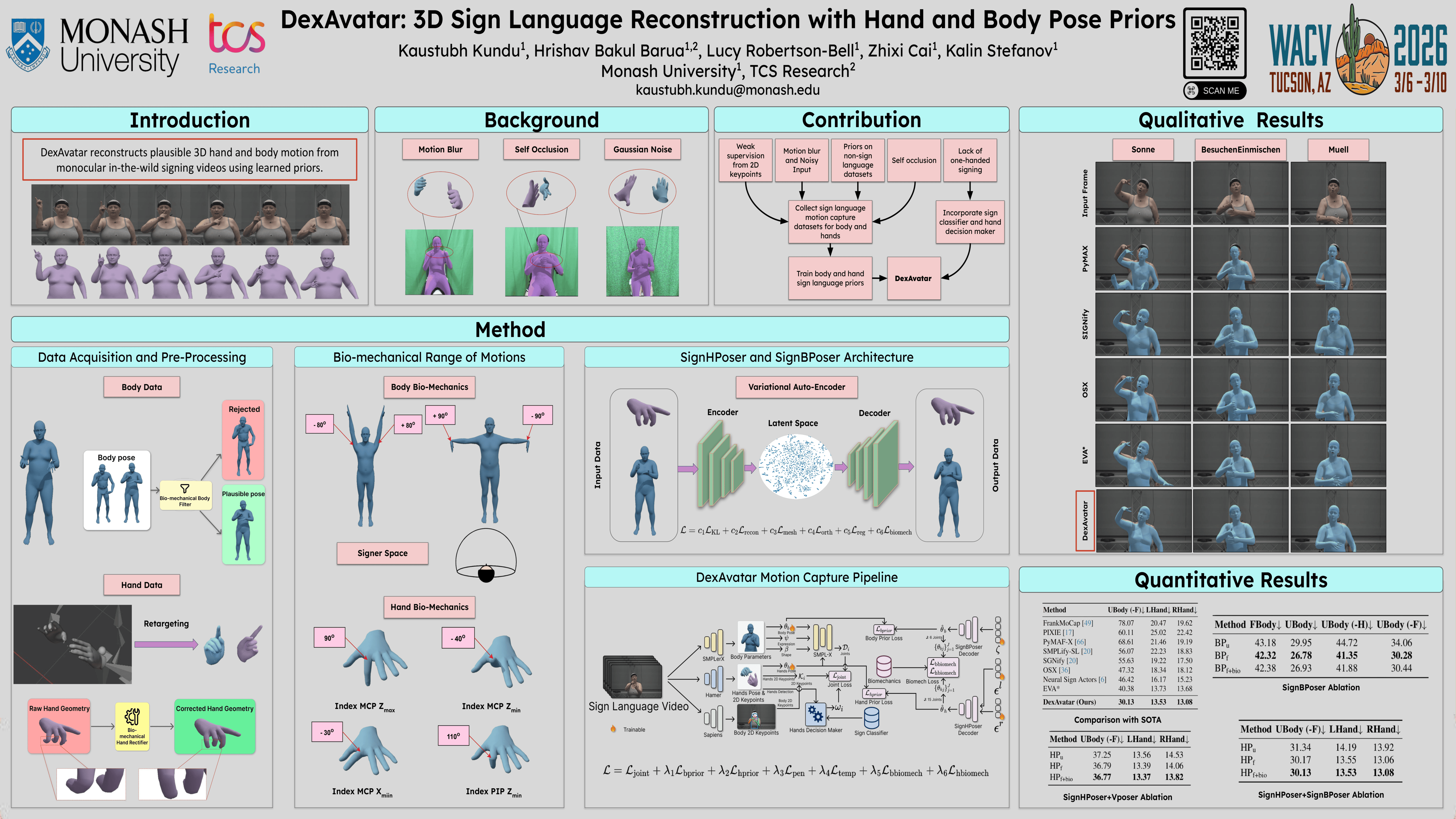
The trend in sign language generation is centered around data-driven generative methods. These methods require vast amounts of precise 2D and 3D human pose data to achieve a generation quality acceptable to the Deaf community. However, currently, most sign language datasets are video-based and limited to automatically reconstructed 2D human poses (i.e., keypoints) and lack accurate 3D information.However, manual production of accurate 2D and 3D human pose information from videos is a labor-intensive process. Furthermore, existing state-of-the-art for automatic 3D human pose estimation from sign language videos is prone to occlusion, noise, and motion blur effects, resulting in poor reconstruction quality. In response to this, we introduce DexAvatar, a novel framework to reconstruct bio-mechanically accurate fine-grained hand articulations and body movements from in-the-wild monocular sign language videos, guided by learned 3D hand and body priors. DexAvatar achieves strong performance in the SGNify motion capture dataset, the only benchmark available for this task, reaching an improvement of 35.11\% in the estimation of body and hand poses compared to the state-of-the-art.