AdaptViG: Adaptive Vision GNN with Exponential Decay Gating
{kind=link}
Abstract
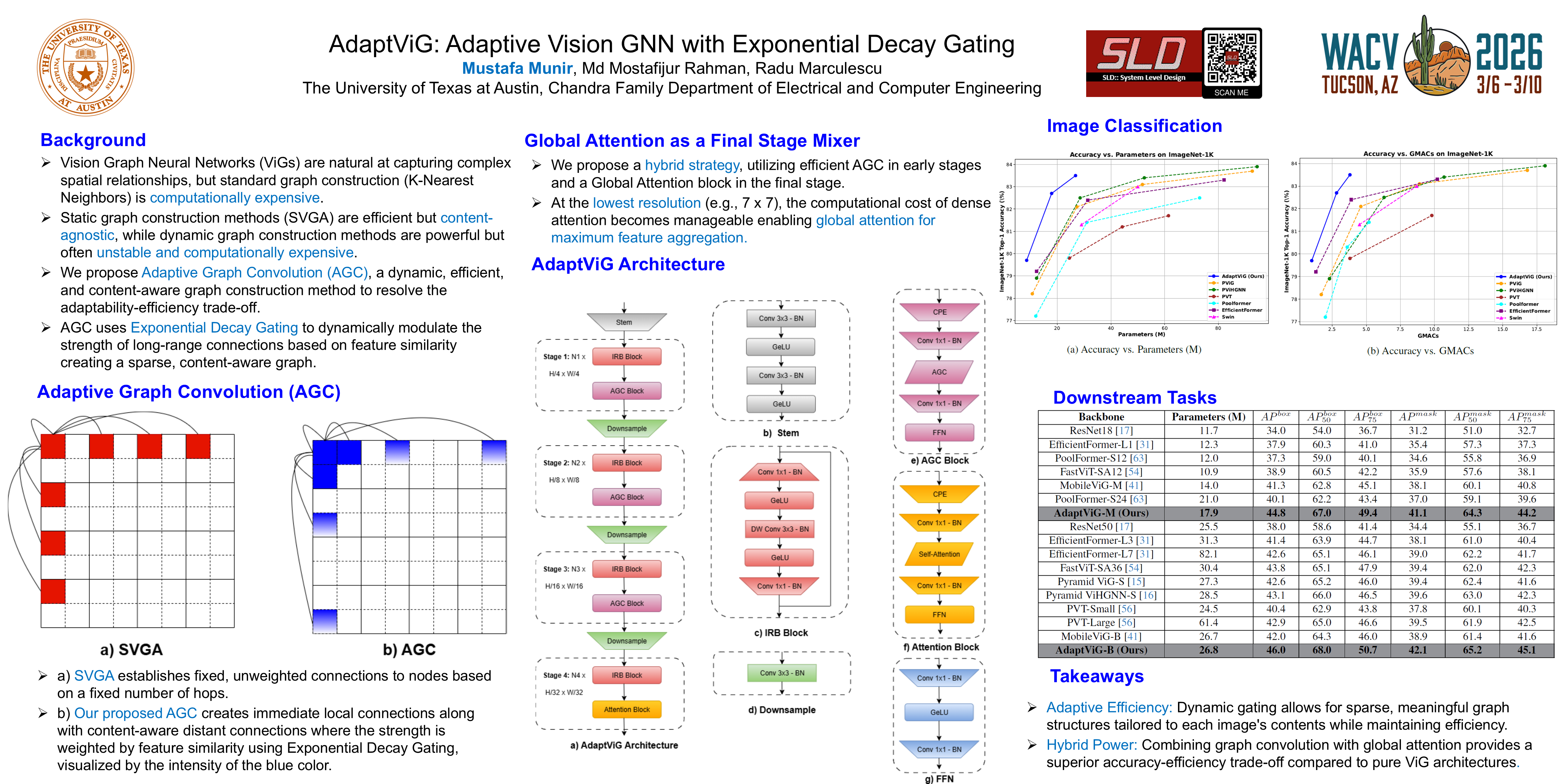
Recent advancements in vision models have been dominated by Transformers and, more recently, Vision Graph Neural Networks (ViGs). While powerful, ViGs often face substantial computational challenges stemming from their graph construction phase, which can hinder their efficiency. To address this issue we propose AdaptViG, an efficient and powerful hybrid Vision GNN that introduces a novel graph construction mechanism called Adaptive Graph Convolution. This mechanism builds upon a highly efficient static axial scaffold and a dynamic, content-aware pruning strategy called Exponential Decay Gating. This gating mechanism uses a division-free, numerically stable function to selectively activate long-range connections based on feature similarity. Furthermore, AdaptViG employs a hybrid strategy, utilizing our efficient gating mechanism in the early stages and a full Global Attention block in the final stage for maximum feature aggregation. Our method achieves a new state-of-the-art trade-off between accuracy and efficiency among Vision GNNs. For instance, our AdaptViG-M achieves 82.7\% top-1 accuracy, outperforming ViG-B by 0.4\% while using 80\% fewer parameters and 84\% fewer GMACs. On downstream tasks, AdaptViG-M obtains 45.8 mIoU, 44.8 APbox, and 41.1 APmask, surpassing the much larger EfficientFormer-L7 by 0.7 mIoU, 2.2 APbox, and 2.1 APmask, respectively, with 78\% fewer parameters.