Vision-informed Semantic Text Alignment for Open-set Recognition in Remote Sensing
{kind=link}
Abstract
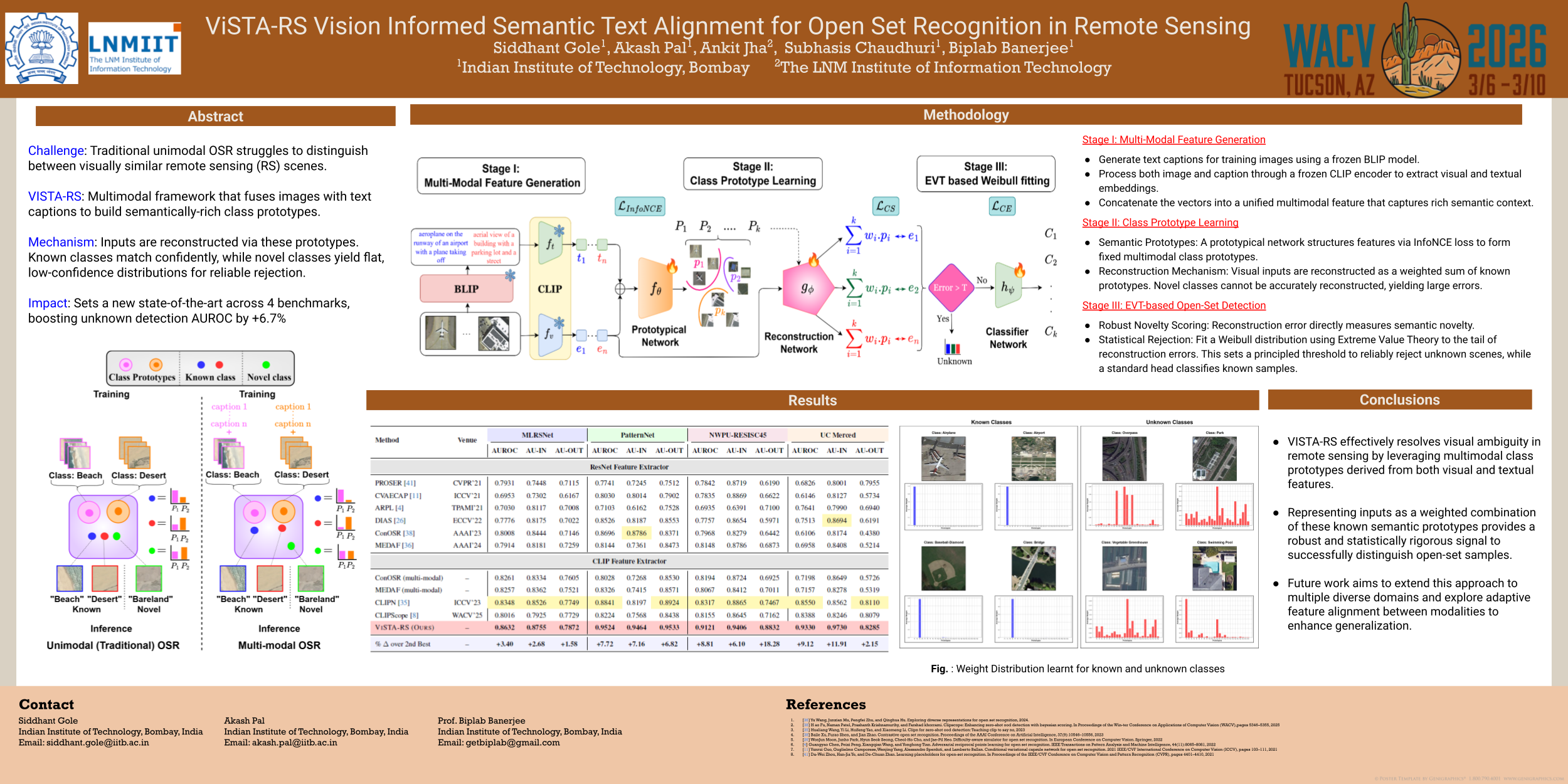
Existing Open-Set Recognition (OSR) methods struggle in remote sensing (RS) as their reliance on unimodal visual features fails to resolve the severe inter-class similarity inherent in overhead imagery. To address this, we propose ViSTA-RS, a novel multimodal framework that leverages semantic context from language to disambiguate visually similar scenes. Our approach first constructs semantically-rich class prototypes by jointly encoding images with generated text captions using a Vision-Language Model. We then introduce a reconstruction-based mechanism where an image's visual embedding is expressed as a weighted combination of these semantic prototypes. The magnitude of the reconstruction error serves as a robust novelty score, with a statistically principled threshold determined by Extreme Value Theory (EVT). This alignment of multimodal semantics with prototype reconstruction is uniquely suited for the fine-grained nature of RS data. On four challenging benchmarks, ViSTA-RS sets a new state-of-the-art, improving the AUROC for unknown detection by a significant 6.7% over leading baselines while maintaining high accuracy on known classes.