Robust Scene Coordinate Regression via Geometrically-Consistent Global Descriptors
{kind=link}
Abstract
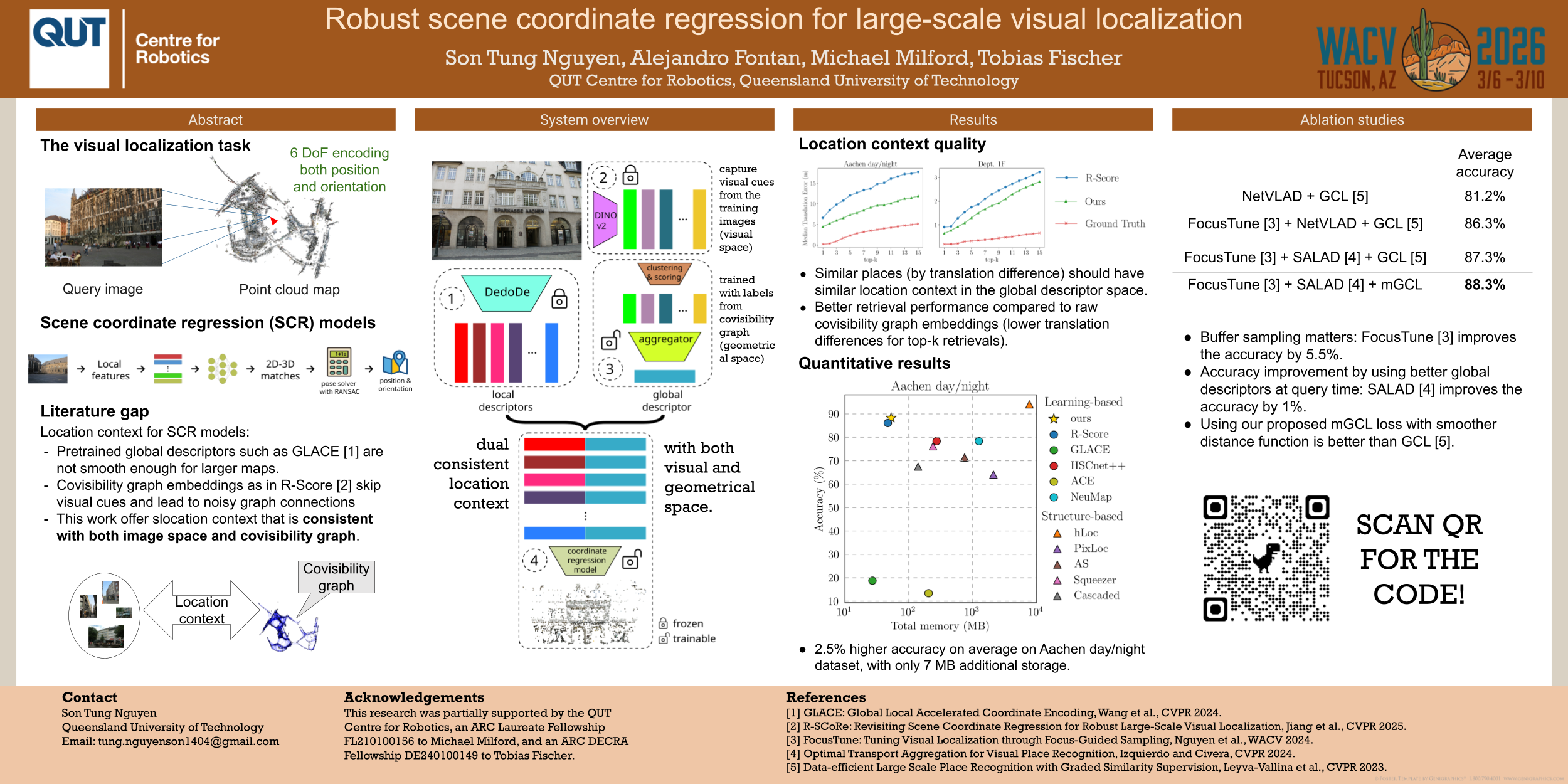
Recent learning-based visual localization methods have shown strong performance by incorporating global descriptors to disambiguate visually similar landmarks in large-scale environments. However, existing approaches typically derive these descriptors from geometrical cues alone (e.g., via a covisibility graph), decoupling them from visual information and limiting their discriminative power. This disconnection reduces robustness under noisy geometrical constraints, particularly when these constraints are derived from potentially unreliable overlapping scores. In this paper, we propose an aggregator module that learns global descriptors consistent with both geometrical relationships and visual similarity. This dual consistency ensures that images receive similar descriptors only when they are both visually similar and structurally connected in the covisibility graph. The aggregator improves descriptor quality by correcting erroneous associations between unrelated image pairs that arise from noisy overlapping scores. We leverage a batch mining strategy based solely on the covisibility graph with a modified contrastive loss, eliminating the need for manual place label annotation and enabling efficient training across diverse environments. Experiments on challenging benchmarks demonstrate that our approach significantly improves localization accuracy in large-scale environments while maintaining similar computational and memory efficiency. The code accompanying this paper will be released.