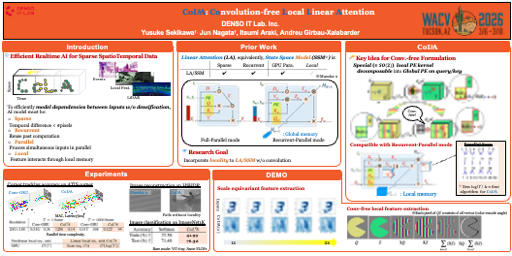
CoL2A: Convolution-free Local Linear Attention for SpatioTemporal Event Processing
Yusuke Sekikawa ⋅ Itsumi Araki ⋅ Jun Nagata ⋅ Andreu Girbau
{kind=link}
Abstract
Linear attention is $\textit{sparse}$, $\textit{recurrent}$, and $\textit{GPU-parallel}$; these are essential features for processing sparse data from event-based cameras. We argue that $\textit{locality}$ is missing to efficiently model event-to-event relationships for continuous spatiotemporal perception. We propose $\textit{CoL}^2\mkern-3mu\textit{A}$ by introducing locality into linear attention without using a computationally demanding convolution operation. The key idea for the convolution-free formulation is restricting the positional embedding local convolutional kernel into the special class which can be decomposed into two global positional embeddings which can be absorbed into query and key; this replaces convolution with a local sum. To the best of our knowledge, $\textit{CoL}^2\mkern-3mu\textit{A}$is the first to equip $\textit{sparsity}$, $\textit{recurrence}$, GPU $\textit{parallelism}$ and $\textit{locality}$, simultaneously. We demonstrate $\textit{CoL}^2\mkern-3mu\textit{A}$'s effectiveness on dense, high-temporal-resolution ($>$ 1000 fps ) prediction task from events, demonstrating real-time capability while maintaining competitive results over the conventional method.
Chat is not available.
Successful Page Load