Training-free Conditional Image Embedding Framework Leveraging Large Vision Language Models
{kind=link}
Abstract
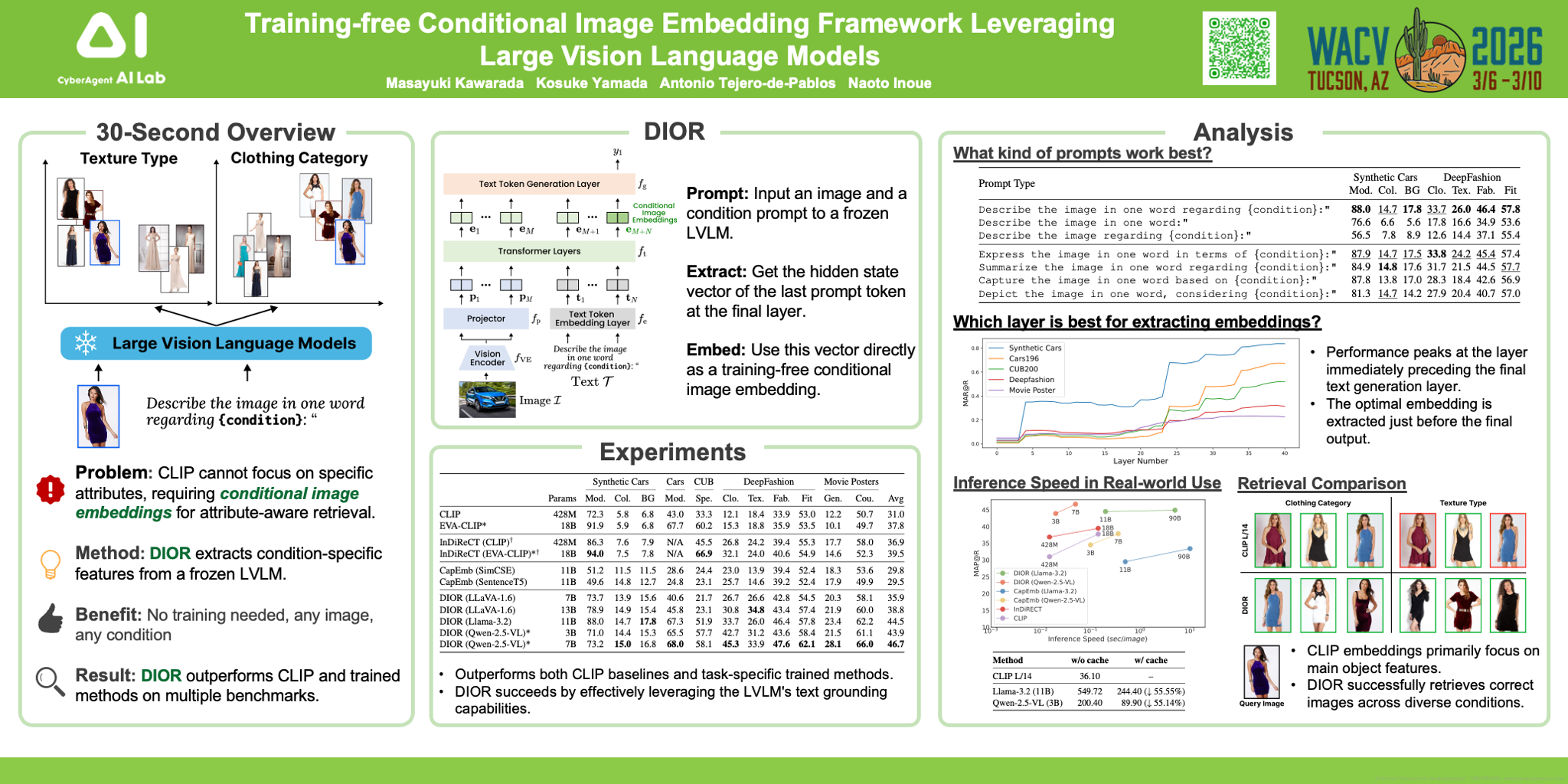
Conditional image embeddings are feature representations that focus on specific aspects of an image indicated by a given textual condition (color, genre), which has been challenging. Although recent vision foundation models, such as CLIP, offer a rich representation of the overall image, they are not amenable to focusing on the specified condition. In this paper, we propose a method to leverage a large vision-language model (LVLM) to generate conditional image embeddings: the DIOR framework. DIOR is a novel training-free approach that prompts the LVLM to describe an image with a single word related to the given condition. The hidden state vector of the LVLM's last token is directly extracted as the conditional image embedding. DIOR provides a versatile solution that can be applied to any image and condition without additional training or specialized prior knowledge. Comprehensive experimental results on conditional image similarity tasks demonstrate that DIOR outperforms existing training-free baselines, including CLIP. Furthermore, DIOR achieves superior performance compared to methods requiring additional training across multiple settings.