VRAgent: Self-Refining Agent for Zero-Shot Multimodal Video Retrieval
{kind=link}
Abstract
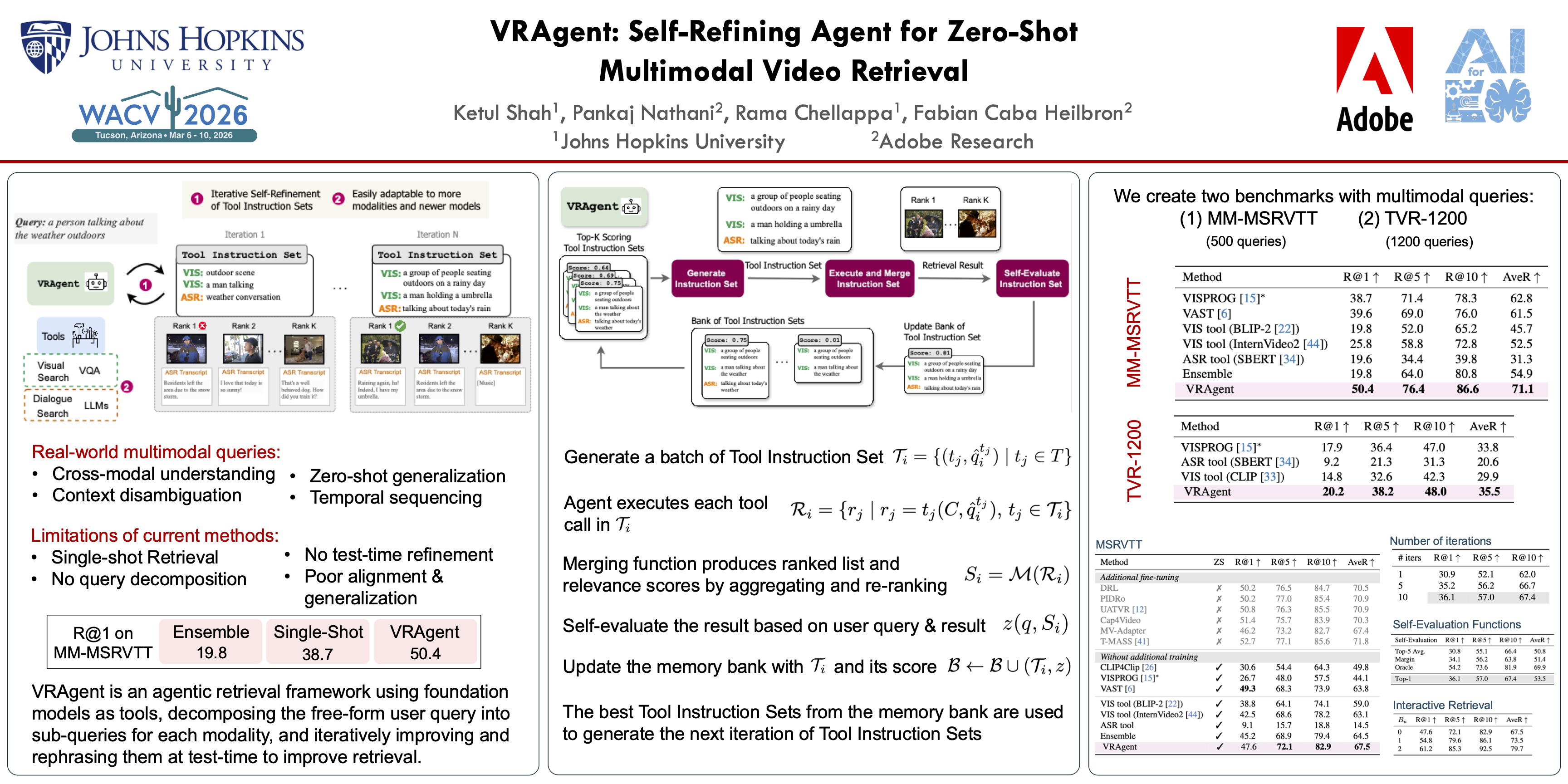
Recent advances in Vision-Language Models (VLMs) and Large Language Models (LLMs) have demonstrated remarkable zero-shot capabilities while becoming increasingly accessible. They have enabled zero‑shot text‑to‑video search, yet they still struggle on real‑world queries that demand temporally aligned reasoning across vision and speech. We present VRAgent, an agentic retrieval framework that leverages a central LLM as a planner which (i) decomposes a free‑form user query into a tool‑instruction set spanning visual, dialogue and other modality‑specific retrievers, and (ii) iteratively self‑refines this plan by scoring its own outputs and rewriting the next instruction set. The resulting closed‑loop optimization acts at test time and requires no additional training data or gradient updates. VRAgent is modular by design—adding a new modality is as simple as adding a corresponding foundation model into the toolbox. On our newly proposed MM‑MSRVTT and TVR‑1200 multimodal benchmarks, VRAgent improves average recall by +8.3\% and +1.7\% over the best zero‑shot baselines, while on single‑modality MSR‑VTT and DiDeMo it obtains consistent gains of +3.7\% and +4.1\%. An interactive variant that asks the user up to two multiple‑choice questions pushes average recall to 79.7\% on MSR‑VTT, underscoring the value of on‑the‑fly human feedback.