Distilling What and Why: Enhancing Driver Intention Prediction with MLLMs
{kind=link}
Abstract
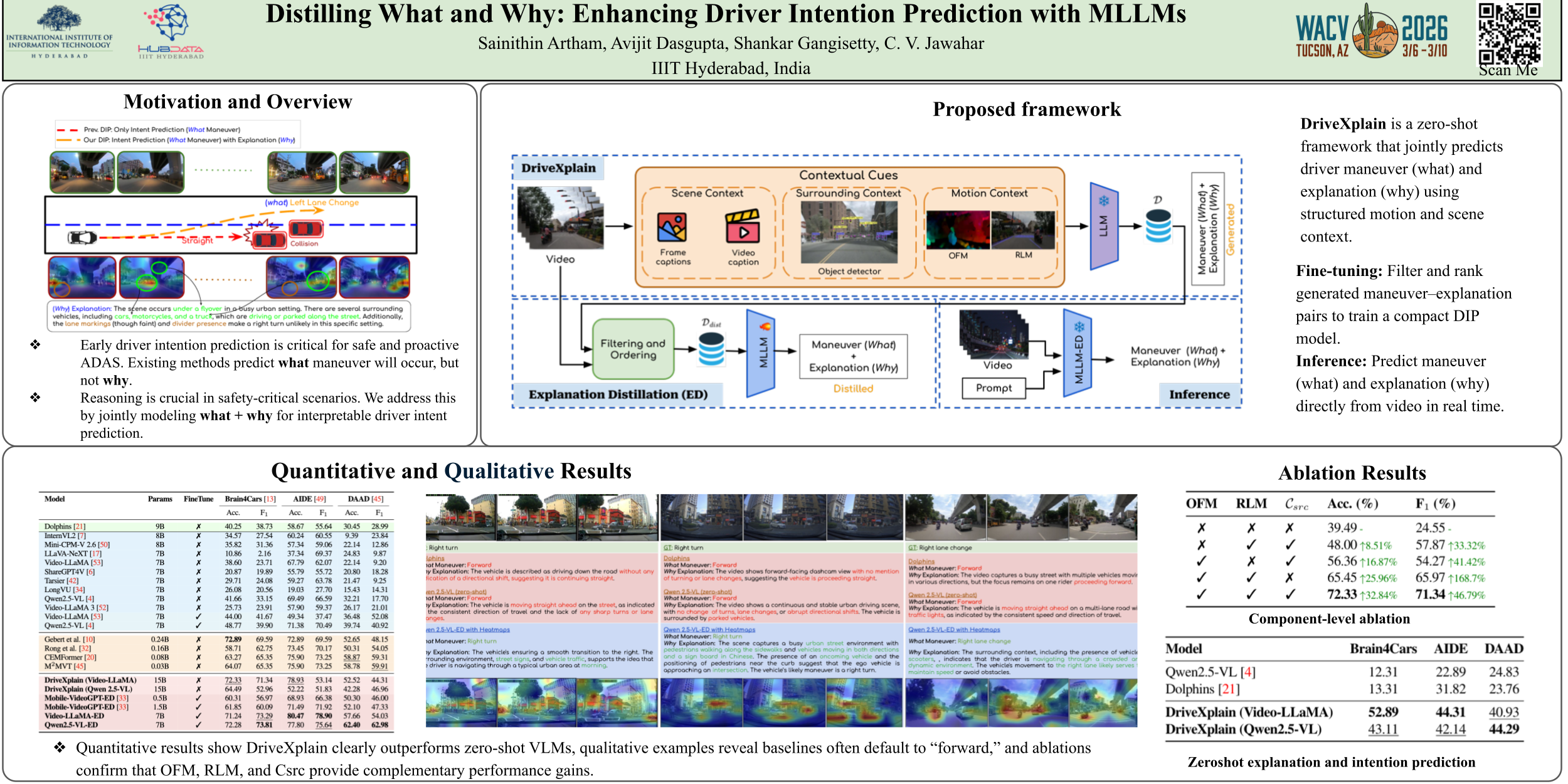
Predicting a drivers’ intent (e.g., turns, lane changes) is a critical capability for modern Advanced Driver Assistance Systems (ADAS). While recent Multimodal Large Language Models (MLLMs) show promise in general vision-language tasks, we find that zero-shot MLLMs still lag behind domain-specific approaches for Driver Intention Prediction (DIP). To address this, we introduce DriveXplain, a zero-shot frame- work based on MLLMs that leverages rich visual cues such as optical flow and road semantics to automatically generate both intention maneuver (what) and rich natural language explanations (why). These maneuver-explanation pairs are then distilled into a compact MLLM, which jointly learns to predict intentions and corresponding explanations. We show that incorporating explanations during training leads to substantial gains over models trained solely on labels, as distilling explanations instills reasoning capabilities by enabling the model to understand not only what decisions to make but also why those decisions are made. Comprehensive experiments across structured (Brain4Cars, AIDE) and unstructured (DAAD) datasets demonstrate that our approach achieves state-of-the-art results in DIP task, outperforming zero-shot and domain-specific baselines. We also present ablation studies to evaluate key design choices in our frame- work. This work sets a direction for more explainable and generalizable intention prediction in autonomous driving systems. We plan to release our codebase to support research.