Boosting Medical Vision-Language Pretraining via Momentum Self-Distillation under Limited Computing Resources
{kind=link}
Abstract
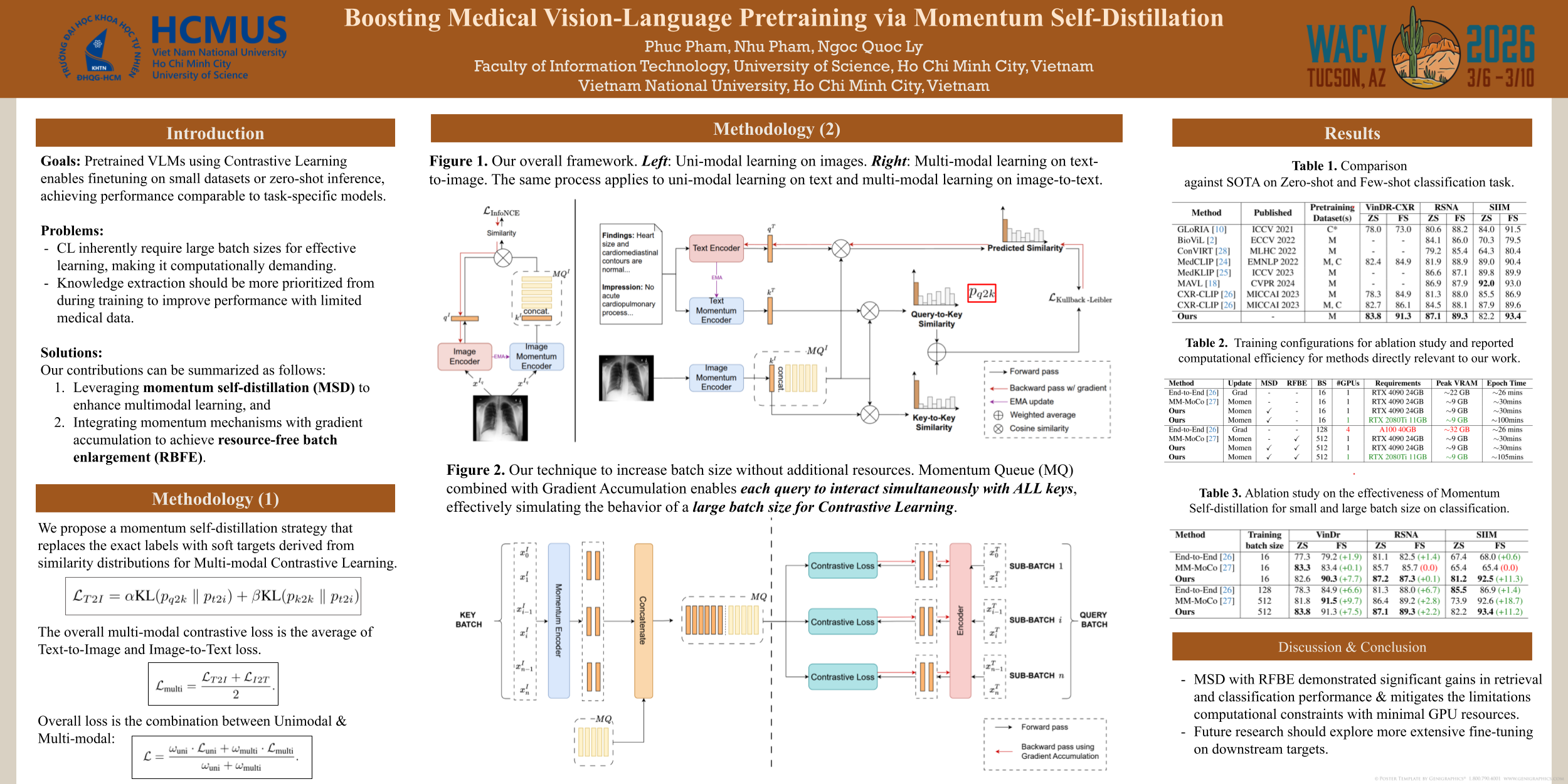
In medical healthcare, obtaining detailed annotations is challenging, highlighting the need for robust Vision-Language Models (VLMs). Pretrained VLMs enable fine-tuning on small datasets or zero-shot inference, achieving performance comparable to task-specific models. On the one hand, contrastive learning (CL) is a key paradigm for training VLMs but inherently requires large batch sizes for effective learning, making it computationally demanding and often limited to well-resourced institutions. On the other hand, with limited data in healthcare, it is important to prioritize knowledge extraction from both data and models during training to improve performance. Therefore, we focus on leveraging the momentum method combined with distillation to simultaneously address computational efficiency and knowledge exploitation. Our contributions can be summarized as follows: (1) leveraging momentum self-distillation to enhance multimodal learning, and (2) integrating momentum mechanisms with gradient accumulation to enlarge the effective batch size without increasing resource consumption. Our method surpasses state-of-the-art (SOTA) approaches in few-shot learning with over 90\% AUC ROC and improves retrieval tasks by 2-3\% across multiple datasets. Importantly, our method achieves high training efficiency with a single GPU while maintaining reasonable training time. Our approach aims to advance efficient multimodal learning by reducing resource requirements while improving performance over SOTA methods.