Model-free Domain Adaptation for Concealed Multimodal Large-Language Models
{kind=link}
Abstract
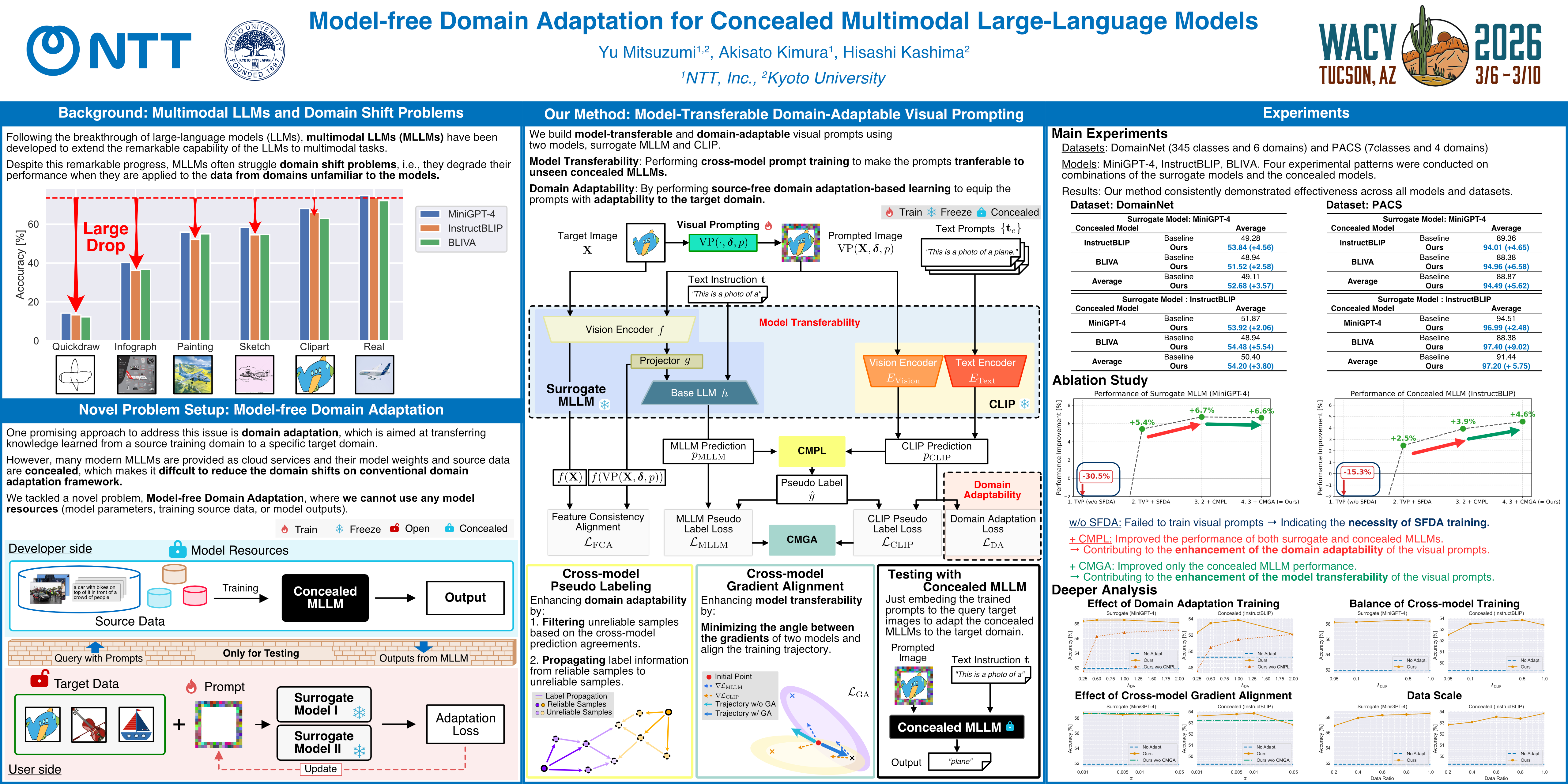
Multimodal large-language models (MLLMs) exhibit remarkable capability for various vision tasks but still struggle with the domain-shift problem, in which their performance degrades for data from unfamiliar domains.Since the latest MLLMs often conceal their model resources (i.e., data, parameters, and outputs) from training purposes, current domain adaptation methods cannot satisfactorily address this problem due to their dependence on those resources.To this end, we introduce a novel domain adaptation setup, ``model-free domain adaptation (MFDA)'' of MLLMs, to investigate whether we can address domain adaptation problems without using any resources of the concealed models.As a proof of concept for MFDA, we built a method named model-transferable domain-adaptable visual prompting (MTDA-VP).In the training, this method executes cross-model visual prompting on surrogate models with a domain adaptation objective so that the visual prompts simultaneously acquire model transferability and domain adaptability.In the testing, we can adapt the concealed MLLMs to the target domain by just inputting the test images with the trained prompt into the models.Besides, we developed two techniques, cross-model pseudo labeling (CMPL) and cross-model gradient alignment (CMGA), to further enhance model transferability and domain adaptability of the visual prompts.We empirically confirmed that MFDA-VP improved the performance of several MLLMs with large margins on two datasets.