Distilling Offline Action Detection Models into Real-Time Streaming Models
{kind=link}
Abstract
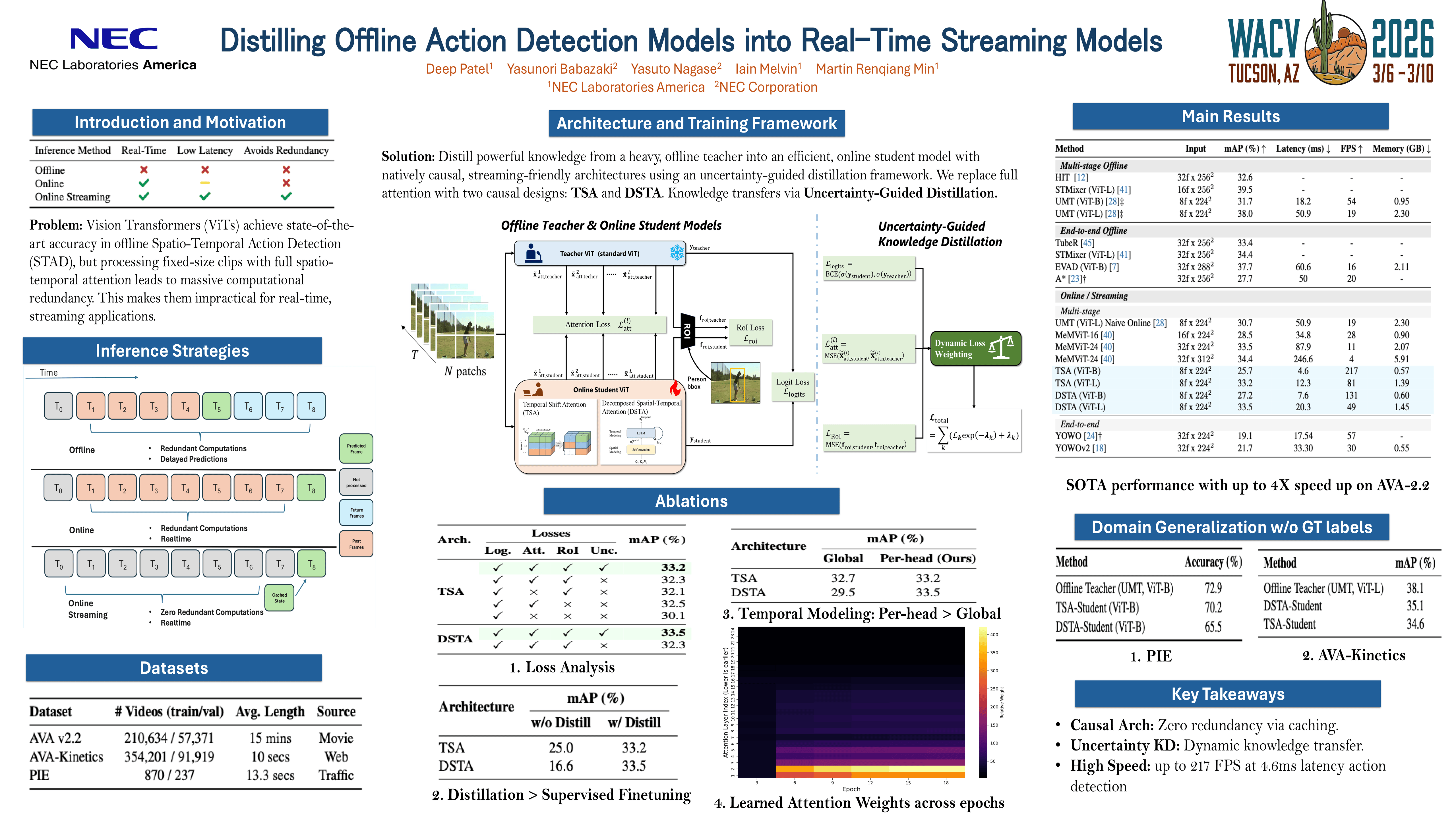
Vision Transformers (ViTs) have achieved state-of-the-art performance in offline video action detection, but their reliance on processing fixed-size clips with full spatio-temporal attention makes them computationally expensive and ill-suited for real-time streaming applications due to massive computational redundancy. This paper introduces a novel framework to adapt these powerful offline models into efficient, online student models through knowledge distillation. We propose two causal, streaming-friendly attention architectures that replace the full self-attention mechanism: (1) a lightweight Temporal Shift Attention that integrates past context with minimal overhead, and (2) a Decomposed Spatial-Temporal Attention that combines intra-frame spatial attention with an LSTM for temporal modeling. Both architectures utilize caching to eliminate redundant operations on a frame-by-frame basis. To maximize knowledge transfer, we introduce an uncertainty-guided distillation process, which formulates the training as a multi-task learning problem. Our resulting models demonstrate significant efficiency gains, achieving up to a 4x improvement in latency and throughput compared to the original offline teacher while ensuring state-of-the-art performance for online methods. Our work provides a practical and effective methodology for deploying high-accuracy transformer models in latency-sensitive, real-world video analysis systems.