Efficient Vision Transformers via Token Merging with Head-wise Attention Correction
{kind=link}
Abstract
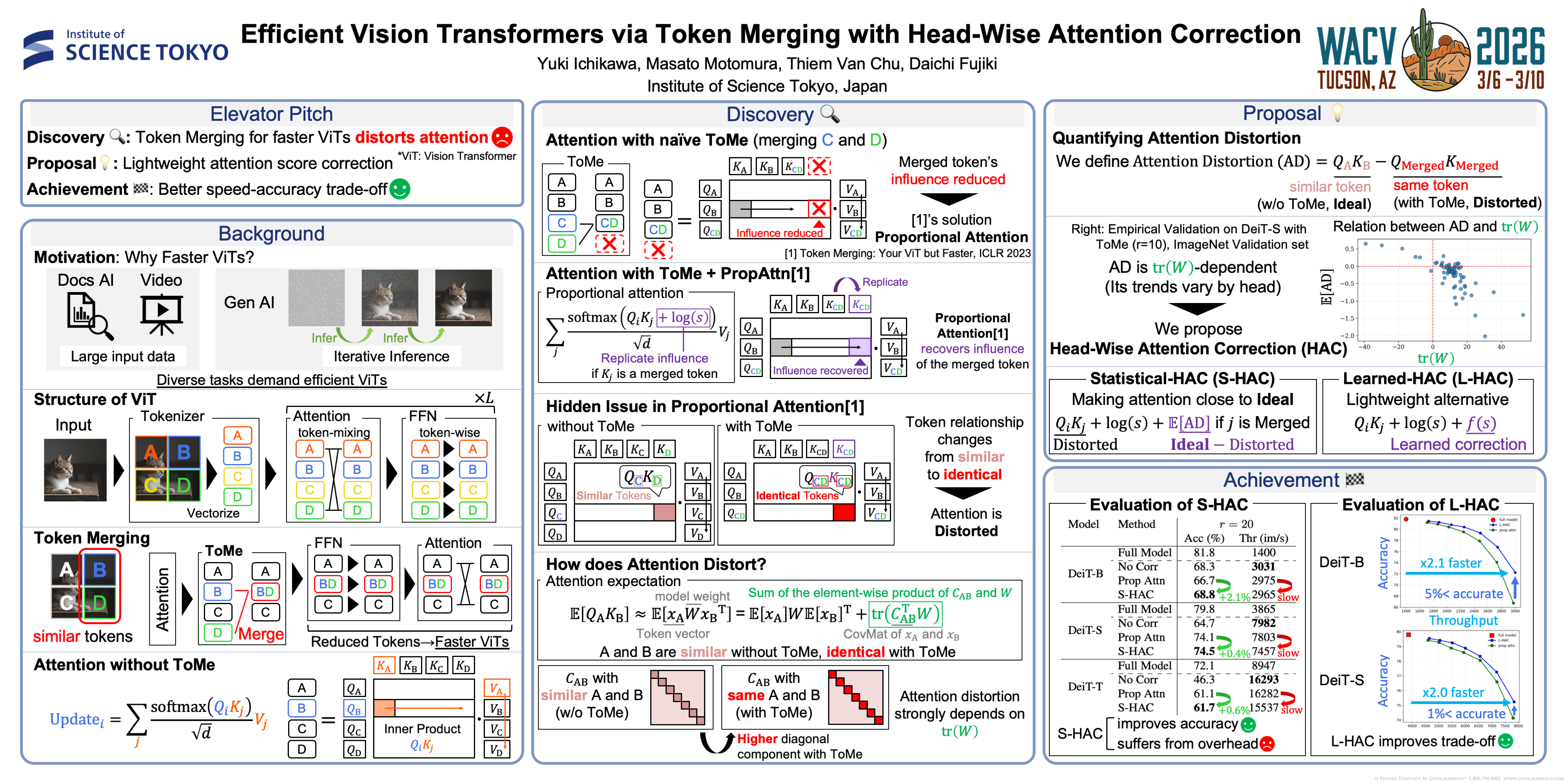
Vision Transformers (ViTs) offer strong performance by modeling global relationships across image patches, but their scalability is limited by the quadratic cost of self-attention. To mitigate this, Token Merging (ToMe) reduces computation by merging similar tokens. This approach relies on proportional attention to preserve the original balance of attention weights after merging. Yet, proportional attention does not fully resolve the attention distortion. It only compensates for a merged token's influence on other tokens, while ignoring the fundamental distortion of the token's own self-attention score. This change creates unaddressed distortions that vary across attention heads. In this work, we conduct a detailed analysis of these attention distortions and reveal their dependence on the query–key projection weights of each head. Based on this finding, we propose Head-wise Attention Correction (HAC), a method that adjusts attention scores after token merging by accounting for head-specific characteristics. HAC effectively mitigates the distortions overlooked by proportional attention, maintaining model accuracy while significantly reducing computation. Experiments on ImageNet demonstrate that our method effectively improves the trade-off between efficiency and performance, advancing the development of efficient Vision Transformers via token merging.