Multi-Modal Soccer Scene Analysis with Masked Pre-Training
{kind=link}
Abstract
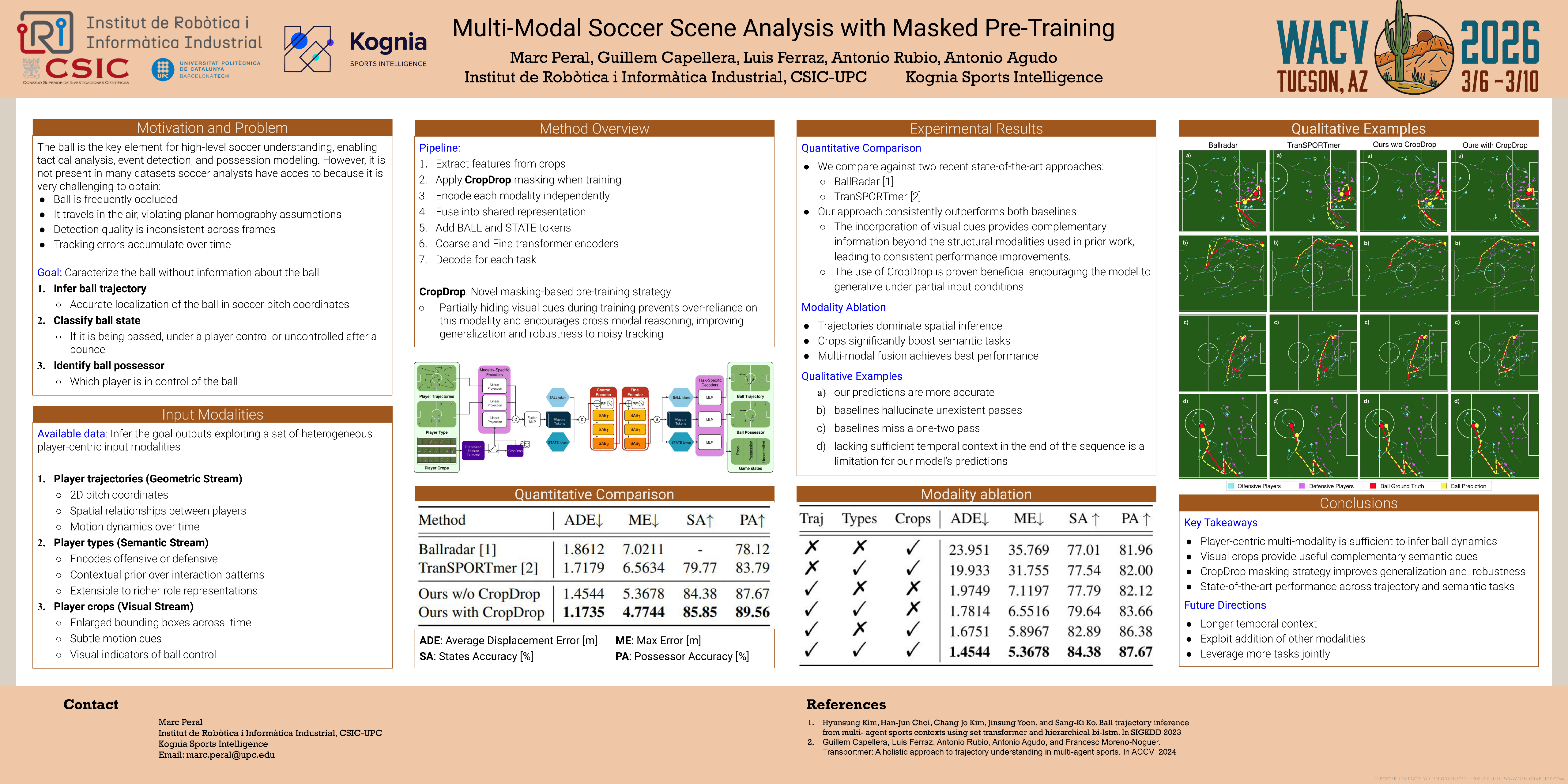
In this work we propose a multi-modal architecture for analyzing soccer scenes from tactical camera footage, with a focus on three core tasks: ball trajectory inference, game state classification, and ball possessor identification. To this end, our solution integrates three distinct input modalities (player trajectories, player types and image crops of individual players) into a unified framework that processes spatial and temporal dynamics using a cascade of sociotemporal transformer blocks. Unlike prior methods, which rely heavily on accurate ball tracking or handcrafted heuristics, our approach infers the ball trajectory without direct access to its past or future positions, and robustly identifies the game state and ball possessor under noisy or occluded conditions from real top league matches. We also introduce CropDrop, a modality-specific masking pretraining strategy that prevents over-reliance on image features and encourages the model to rely on cross-modal patterns during pretraining. We demonstrate the effectiveness of our approach on a large-scale dataset showing substantial improvements over state-of-the-art baselines in all tasks. Our results highlight the benefits of combining structured and visual cues in a transformer-based architecture, and the importance of realistic masking strategies in multi-modal learning.