2S-CEDiff: A Two-Stage Diffusion Framework for Generating High-Fidelity Contrast-Enhanced CT Images from Non-Contrast Scans
{kind=link}
Abstract
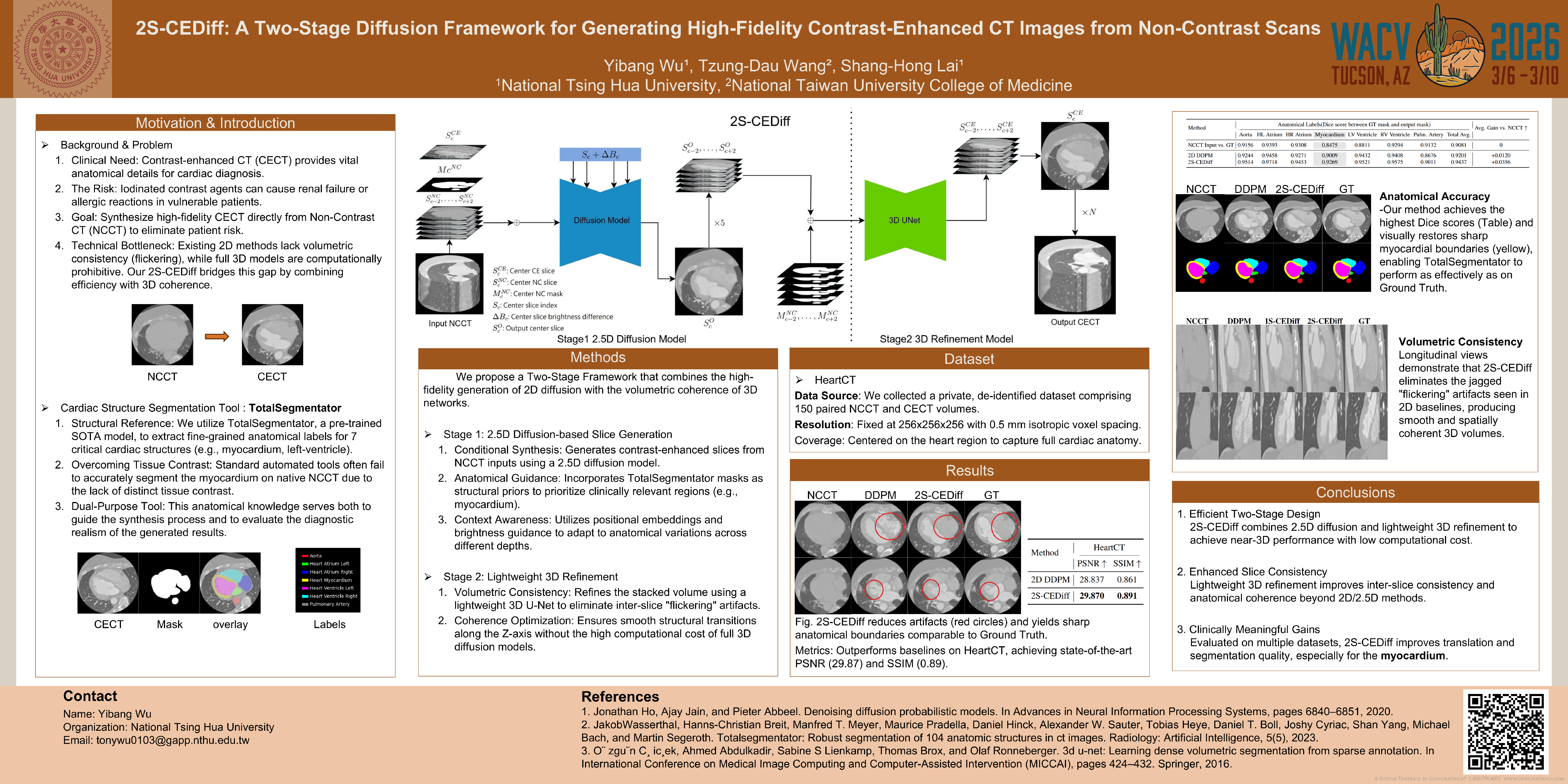
Contrast-enhanced Computed Tomography (CT) plays a vital role in modern medical diagnostics, particularly in cardiovascular assessment. However, the use of intravenous contrast agents can pose potential health risks for vulnerable patient populations. To address this limitation, we present 2S-CEDiff, a clinically-inspired image translation framework that synthesizes high-fidelity contrast-enhanced 3D CT volumes from non-contrast inputs. Our method adopts a two-stage architecture. The first stage employs a 2.5D diffusion model to generate anatomically accurate slice-wise predictions, guided by cross-attention-based positional conditioning and structural priors derived from segmentation masks produced by a pre-trained TotalSegmentator model. The second stage involves applying a 3D UNet model trained with a multi-objective loss that jointly optimizes pixel-level fidelity and volumetric coherence.We evaluate 2S-CEDiff on an in-house paired 3D cardiac CT dataset, where it achieves state-of-the-art performance in PSNR (29.87), SSIM (0.89), and inter-slice coherence. Moreover, the synthesized contrast-enhanced images significantly enhance downstream anatomical segmentation accuracy, improving the overall Dice score to 0.9447 and yielding a substantial +0.0798 increase in myocardium segmentation performance with TotalSegmentator — underscoring their clinical utility and translational potential.