RPT-SR: Regional Prior attention Transformer for infrared image Super-Resolution
{kind=link}
Abstract
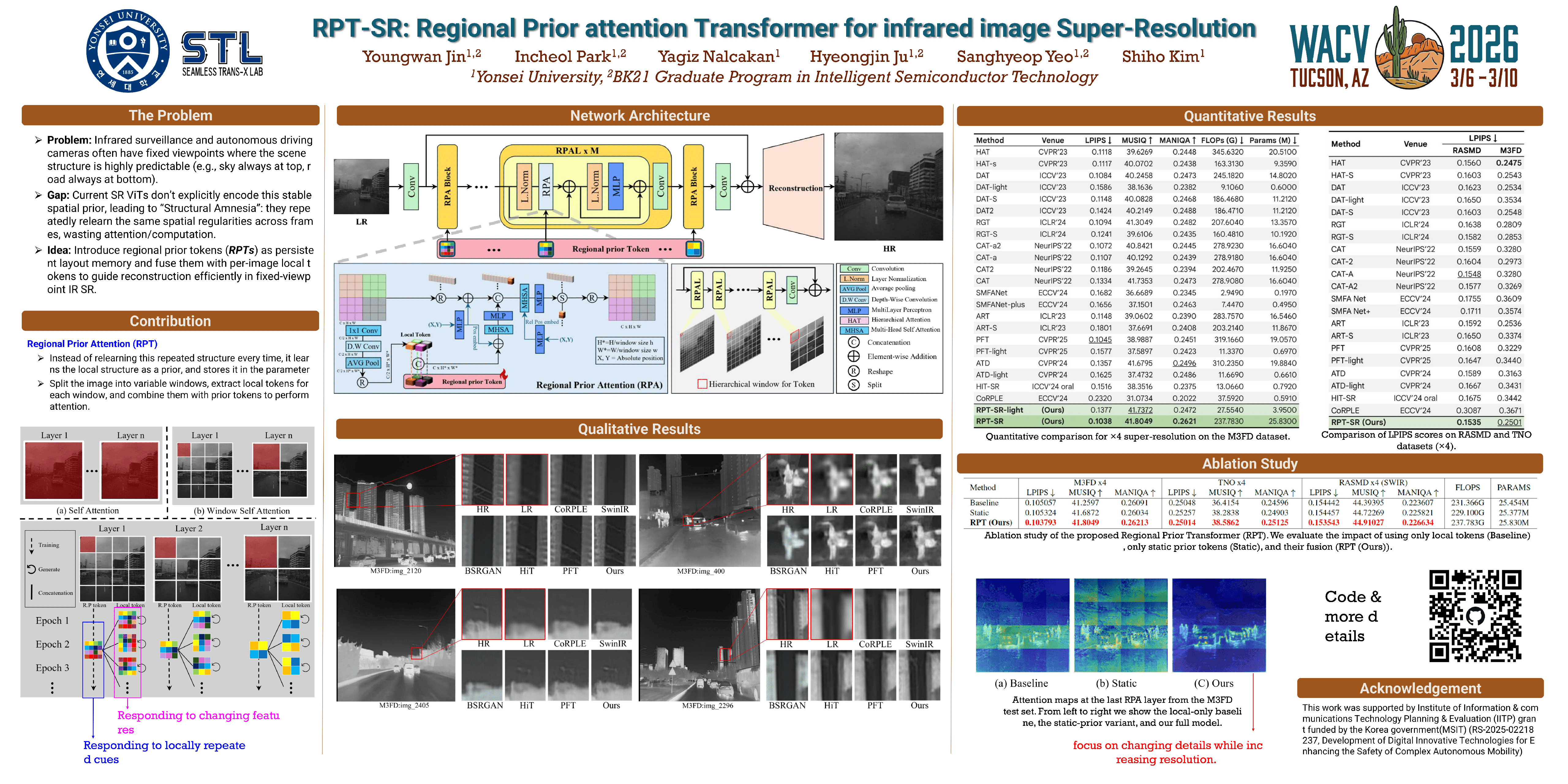
General-purpose super-resolution models, particularly Vision Transformers, have achieved remarkable success but exhibit fundamental inefficiencies in common infrared imaging scenarios like surveillance and autonomous driving, which operate from fixed or nearly-static viewpoints. These models fail to exploit the strong, persistent spatial priors inherent in such scenes, leading to redundant learning and suboptimal performance. To address this, we propose the Regional Prior attention Transformer for infrared image Super-Resolution (RPT-SR), a novel architecture that explicitly encodes scene layout information into the attention mechanism. Our core contribution is a dual-token framework that fuses (1) learnable, regional prior tokens, which act as a persistent memory for the scene's global structure, with (2) local tokens that capture the frame-specific content of the current input. By utilizing these tokens into an attention, our model allows the priors to dynamically modulate the local reconstruction process. Extensive experiments validate our approach. While most prior works focus on a single infrared band, we demonstrate the broad applicability and versatility of RPT-SR by establishing new state-of-the-art performance across diverse datasets covering both Long-Wave (LWIR) and Short-Wave (SWIR) spectra. Our code will be publicly available.