Leveraging Pretrained Representations for Cross-Modal Point Cloud Completion
{kind=link}
Abstract
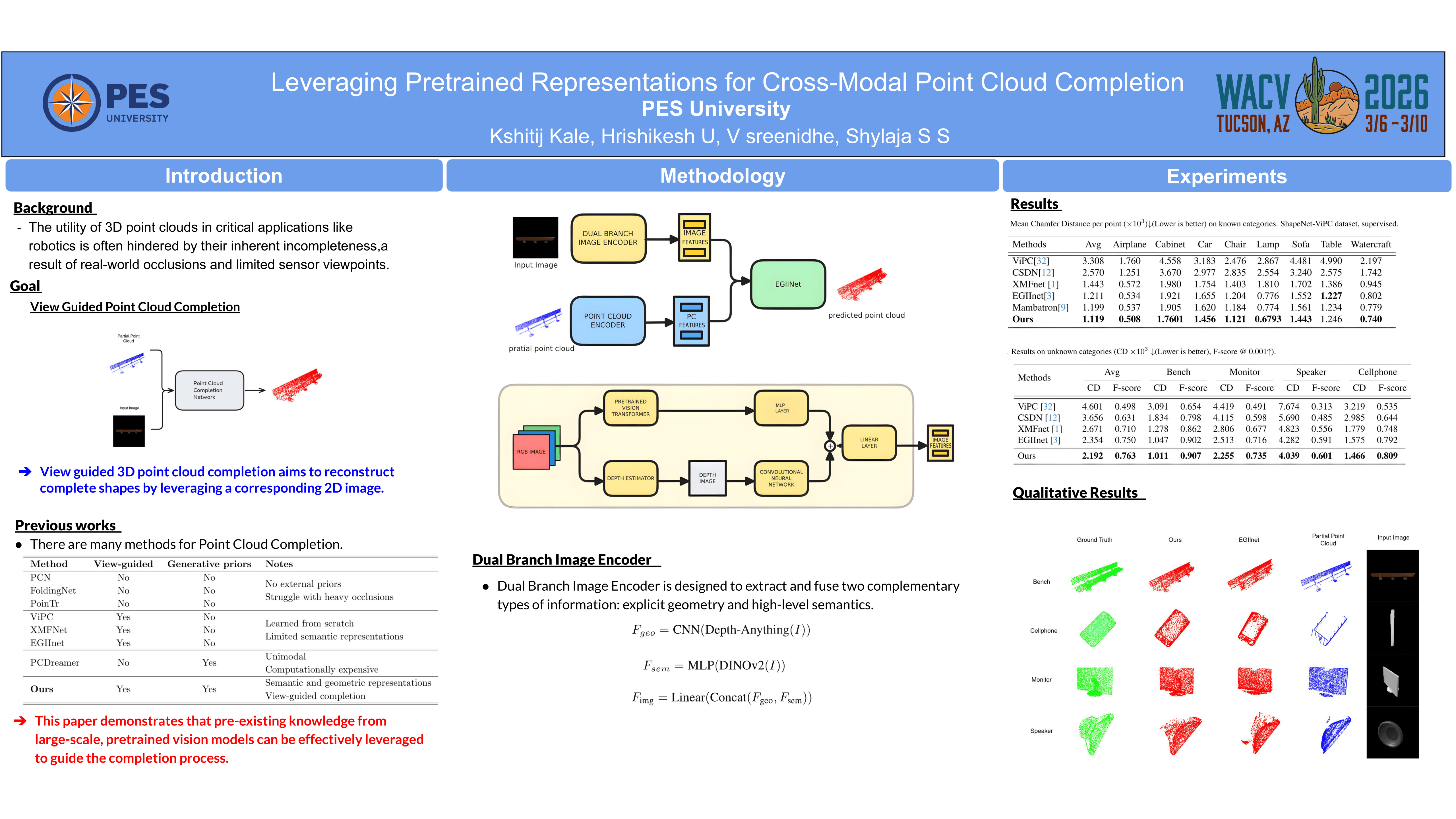
The utility of 3D point clouds in critical applications like robotics is often hindered by their inherent incompleteness, a result of real-world occlusions and limited sensor viewpoints. To overcome this, image-guided 3D point cloud completion aims to reconstruct complete shapes by leveraging a corresponding 2D image. However, current methods typically train a cross-modal network from scratch, often failing to capture the high-level semantic context and complex structural information required for robust reconstruction. This paper challenges that paradigm by demonstrating that preexisting knowledge from large-scale, pretrained vision models can be effectively leveraged to guide the completion process. We introduce a novel Dual Branch Image Encoder, a dedicated module designed to extract and fuse rich semantic priors from a pretrained Vision Transformer with geometric depth cues. This fused representation provides a powerful, multifaceted guide that is integrated into EGIInet, a state-of-the-art point cloud completion network. Our experiments show that by conditioning the completion on these strong, pretrained priors, our method outperforms existing state-of-the-art techniques by 7\% without changing the rest of the architecture, producing more semantically coherent and structurally accurate 3D shapes.