TalkingHeadBench: A Multi-Modal Benchmark & Analysis of Talking-Head DeepFake Detection
{kind=link}
Abstract
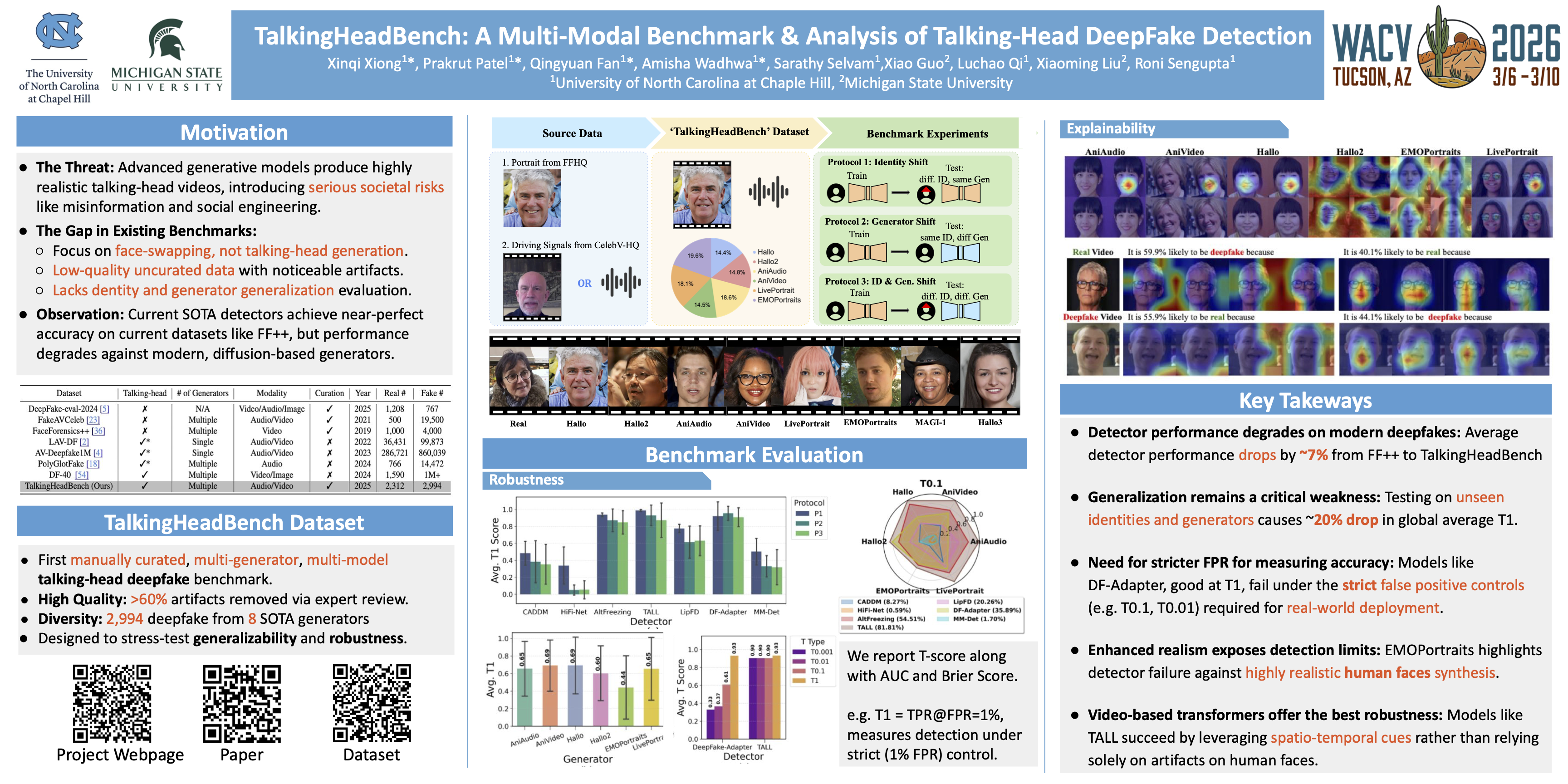
The rapid advancement of talking-head deepfake generation fueled by advanced generative models has elevated the realism of synthetic videos to a level that poses substantial risks in domains such as media, politics, and finance. However, current benchmarks for deepfake talking-head detection fail to reflect this progress, relying on outdated generators and offering limited insight into model robustness and generalization. We introduce TalkingHeadBench, a new benchmark designed to address this gap, featuring talking-head videos from six modern generators, with an additional two emerging generators used exclusively for testing generalization. The dataset is built on an expert-led curation process that filters over 60\% of samples to remove videos with noticeable artifacts, presenting a more difficult challenge for detectors. Our evaluation protocols are designed to measure generalization across identity and generator shifts. Benchmarking seven state-of-the-art detectors reveals that models with high accuracy on older datasets like FaceForensics++ show a significant performance drop on our curated data, particularly at strict false positive rates (e.g., TPR@FPR=0.1\%). In addition, we identify a trend where detectors focus on background cues instead of facial features using Grad-CAM visualization. The dataset will be made available in open access with all data splits and protocols. Our benchmark aims to accelerate research towards more robust and generalizable detection models in the face of rapidly evolving generative techniques.