Lose Your Self (LoYS): an adversarial entropy-based unsupervised approach for model debiasing
{kind=link}
Abstract
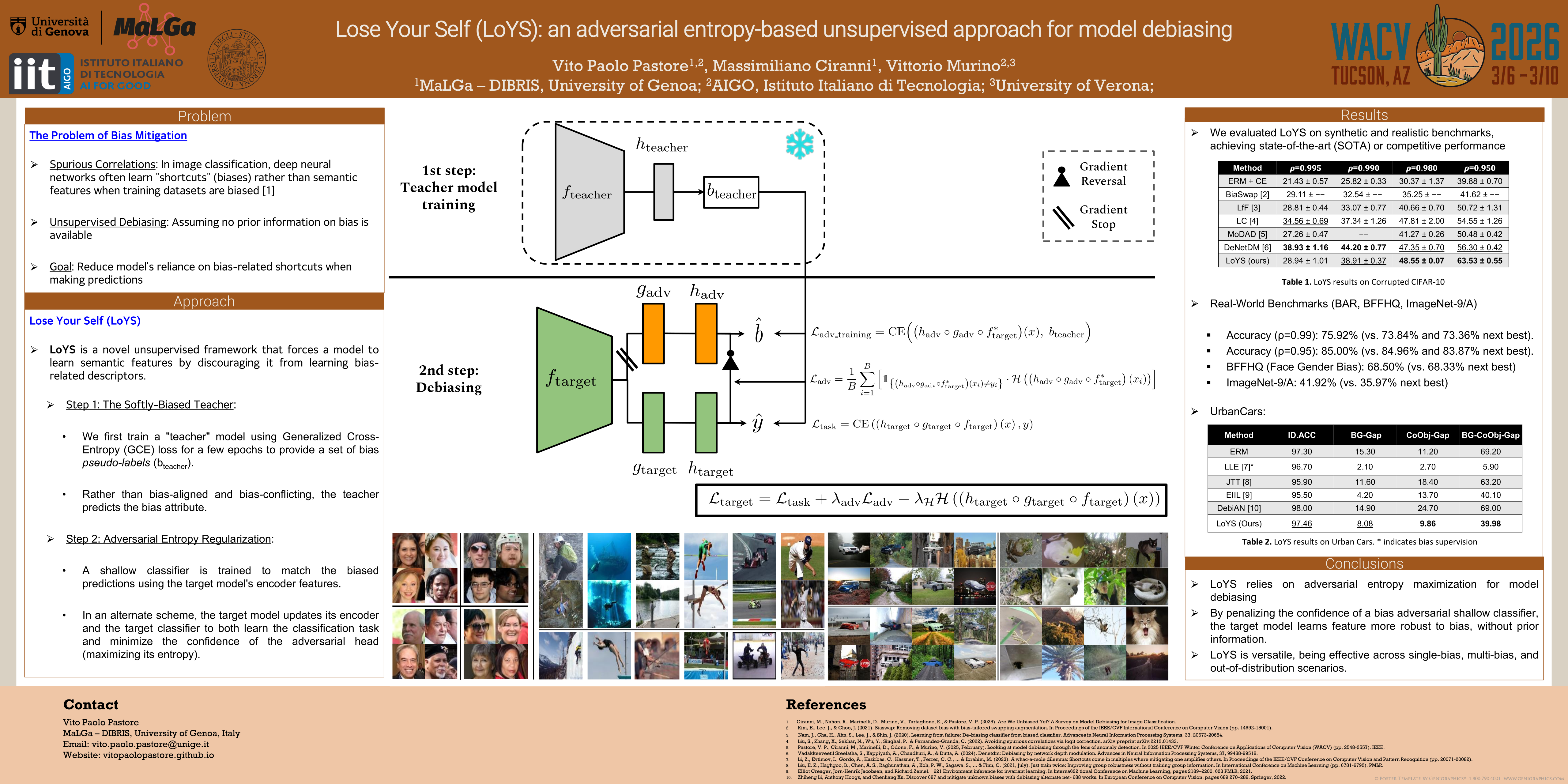
When spurious correlations between targets and data are present in training samples, deep neural networks may struggle to generalize, typically learning shortcuts corresponding to such undesired correlations (i.e., the bias), rather than fundamental target attributes. If bias attributes are assumed to be known, several strategies can be applied to mitigate a model's dependency on bias, including upsampling or upweighting samples with no bias. However, this is hardly the case in real-world scenarios, and alternative unsupervised debiasing approaches have been proposed in recent years, assuming no bias information is available. In this work, we propose Lose Your Self (LoYS), a novel bias-unsupervised approach for model debiasing. The main design strategy in LoYS aims to force a model learning semantic features, discouraging it from learning bias-related descriptors, specifically focusing on the target classifier confidence. Exploiting an adversarial scheme based on entropy loss, against a shallow auxiliary classifier trained to match the predictions of a pre-trained biased model, and entropy regularizations, our experiments show how LoYS is competitive or outperforms state-of-the-art methods, on several common benchmarks.