Subspace-Guided Knowledge Distillation for Efficient Model Transfer
{kind=link}
Abstract
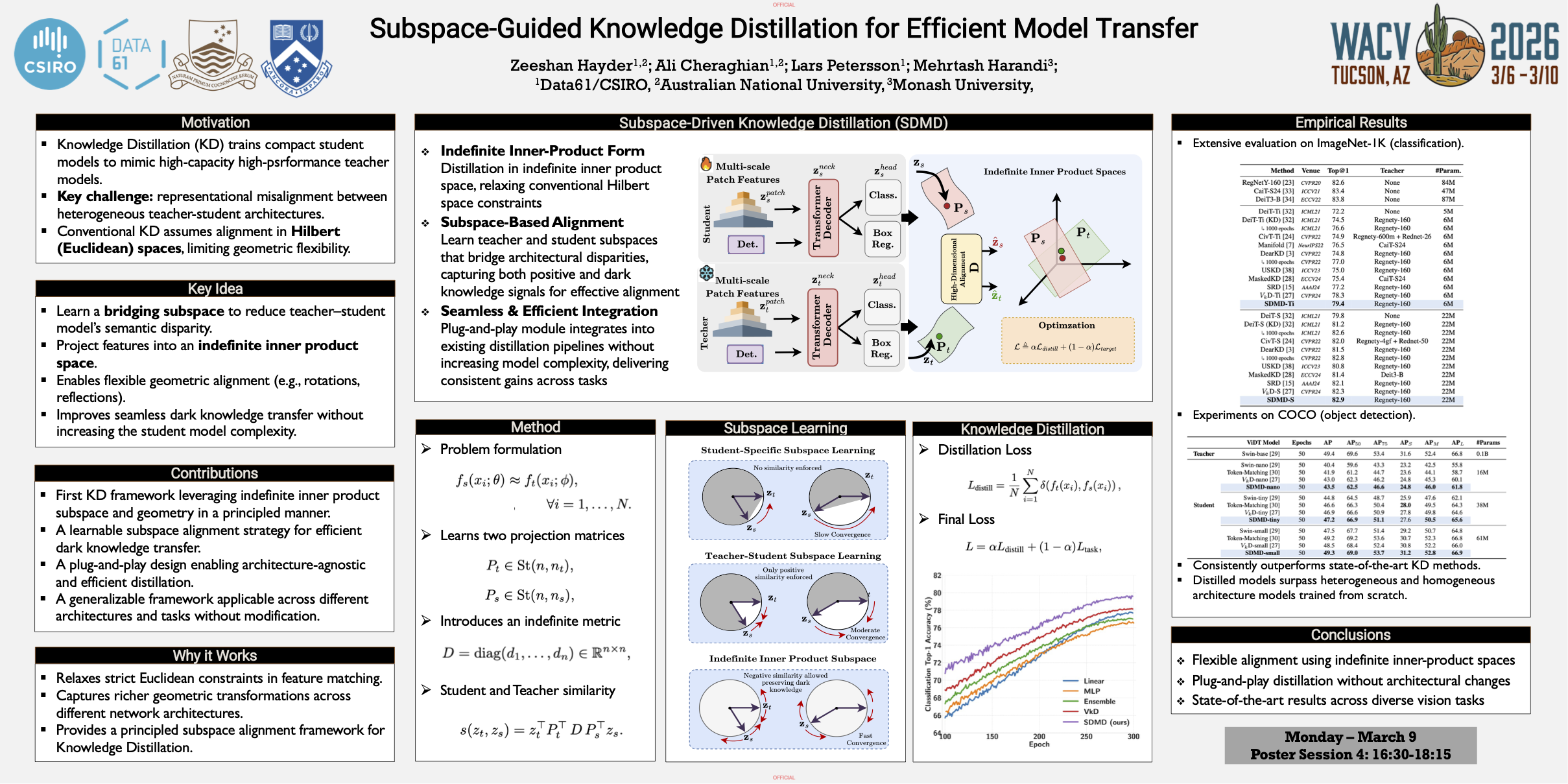
Compact models can be effectively trained via Knowledge Distillation (KD), where a lightweight student model learns to replicate the behavior of a larger, high-performing teacher. A persistent challenge in KD lies in the misalignment between the representational spaces of teacher and student networks, especially when they differ in architecture or capacity. To address this, we propose Subspace-Driven Knowledge Distillation (SDMD), a novel framework that mitigates representational disparity by projecting features into an indefinite inner product space. This relaxation from traditional Hilbert spaces enables more flexible geometric alignment, capturing transformations such as rotations and reflections that are often necessary for accurate knowledge transfer. By learning a subspace that bridges the semantic gap between teacher and student, SDMD facilitates more effective distillation without increasing model complexity. We validate SDMD through extensive experiments on large-scale image classification (ImageNet-1K) and object detection (COCO), where it consistently outperforms existing distillation methods. Notably, SDMD-trained models not only achieve state-of-the-art results in distilled settings but also surpass the performance of equivalent models trained from scratch, highlighting the strength of our subspace-based alignment strategy.