Diffusion Noise Optimization for Synthetic VLM Training
{kind=link}
Abstract
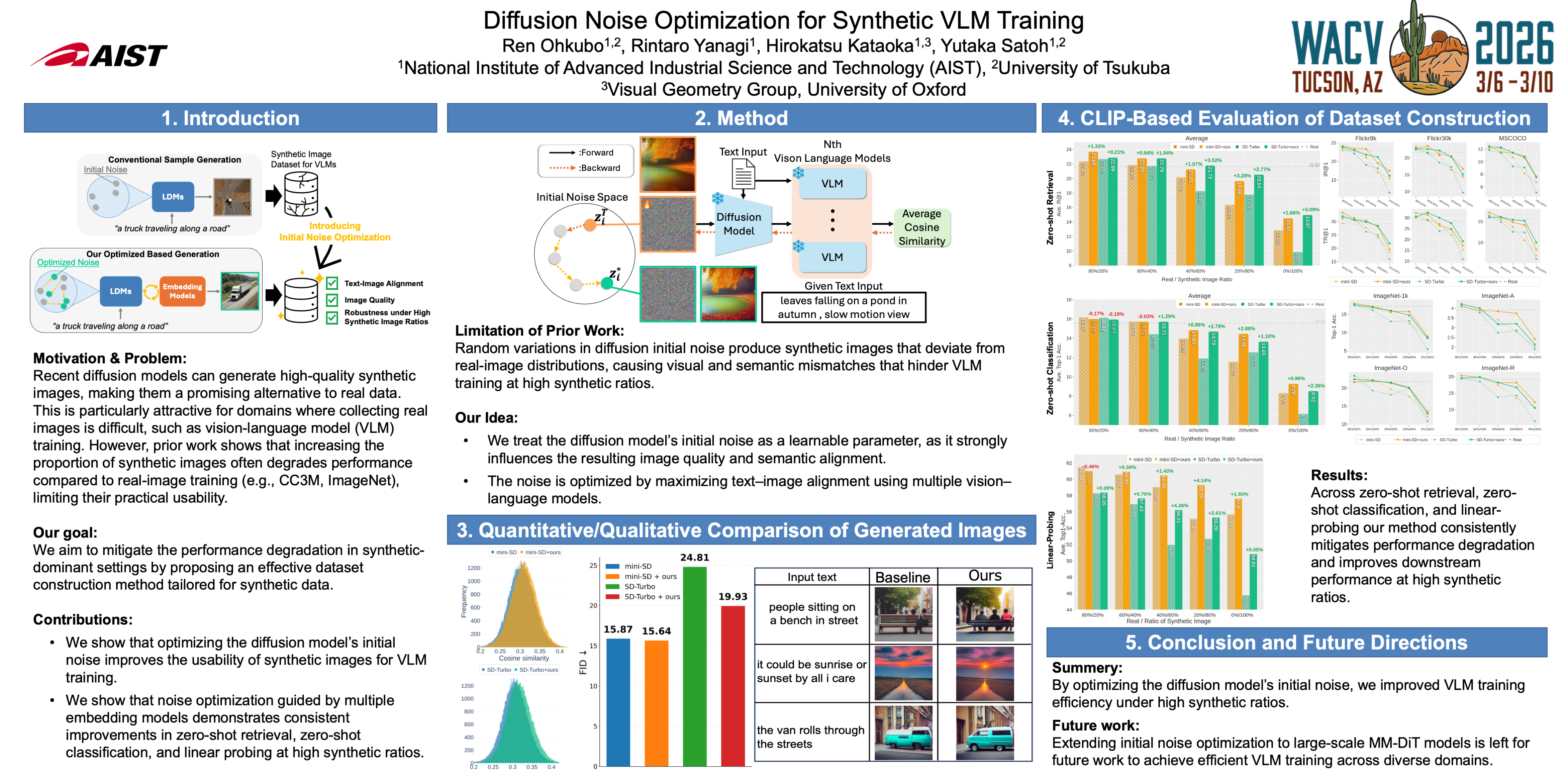
Recent advances in image generation models have enabled the production of high-quality images, making synthetic images a promising alternative to real images for dataset construction. However, a critical challenge remains in that the performance of Vision–Language Models (VLMs) tends to degrade as the proportion of synthetic images in a dataset increases in conventional approaches. To alleviate the challenge, we introduce a plug-and-play dataset construction framework that enhances text-to-image diffusion models by optimizing their initial noise. Our method treats the initial noise as a learnable parameter and iteratively updates it to maximize text–image alignment based on multiple embedding models without retraining the generator. Since the initial noise plays a crucial role in determining the quality of the synthetic image, its optimization enables the search for initial conditions that yield semantically faithful and realistic images. By improving FID and text–image alignment compared to conventional latent diffusion model (LDM)-based methods, our approach produces synthetic images better suited for training. When CLIP models were trained on such images, it achieved up to +5.09\% higher Average R@1 in zero-shot retrieval, +2.88\% higher Average top-1 accuracy in zero-shot classification, and +5.05\% higher performance in linear-probing. These results demonstrate that initial noise optimization is an effective and scalable strategy for enabling robust VLM training with synthetic images.